
Connectionist Temporal Classification
Dare I say, CTC is as crucial as transformers in language models.
CTC can be used for detecting cursive handwriting, sequence based problems, digital signal processing especially in automatic speech recognition(ASR).
So, what is the base of CTC?
They are Recurrent neural network (RNN)
We will try looking for ASR, that is speech to text and what is speech made of?
Yes audio…
Audio can be in form of wave or digital signal
This raw audio is directly given as an input to the rnn.
But it would be impractical for rnn to take whole audio at once, so the audio is split into frames
Did you know: although digital signals look continuous, they are not! They are infact discrete in both time and amplitude

These frames are given as inputs to the rnn, one by one…
What are these outputs (y1,y2,y3)..?
These outputs are classified labels…
Now what are this?
Let us take an example, Sentence = ‘I am Batman’
Classification labels are the unique characters either in a sentence or a corpus,so for the senenece above, the labels are I,a,m,B,t,n
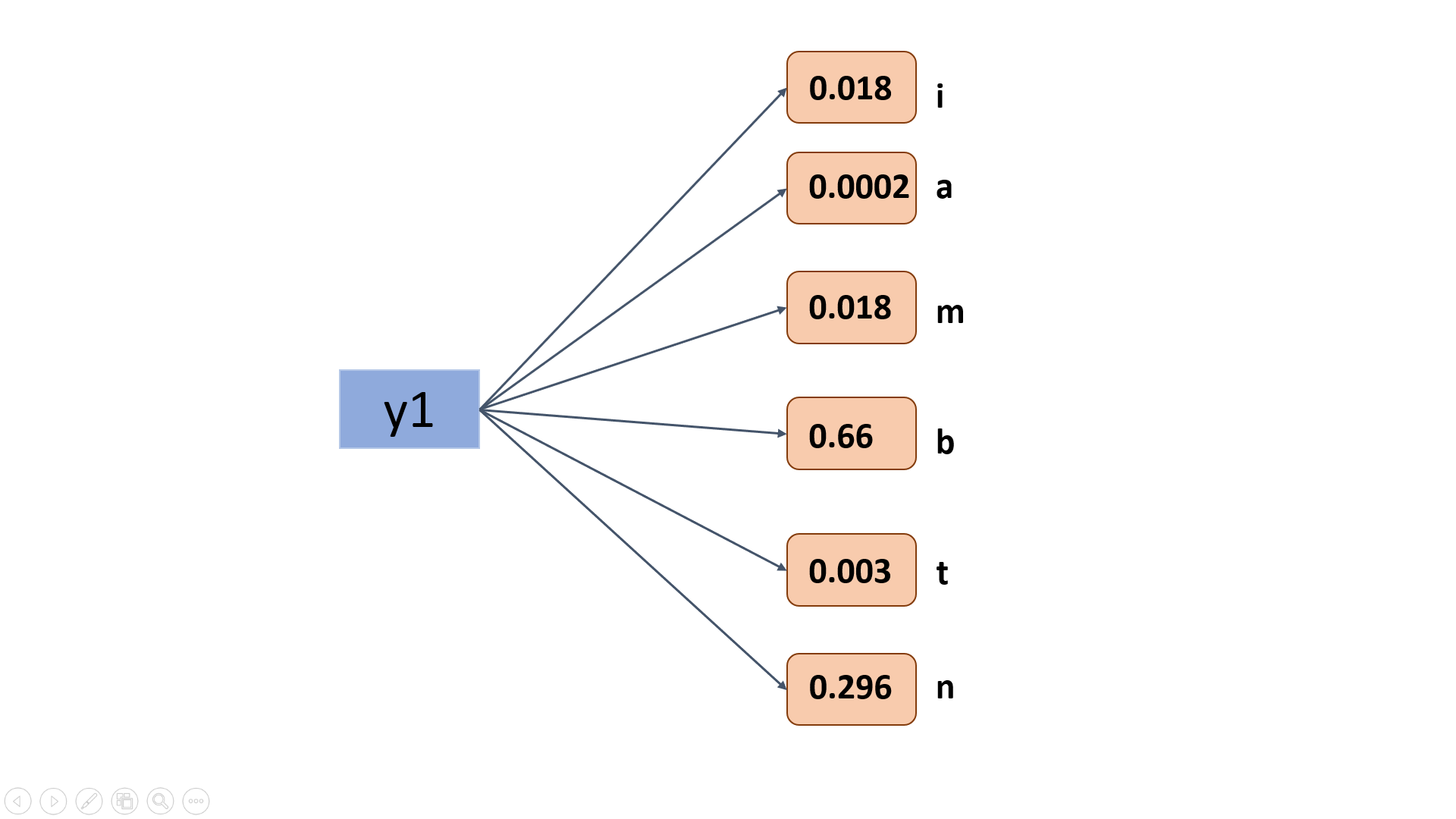
Let us see what are the classification labels from y1
The label values are random consisting both positive and negative values.
Now, what is the problem with the above values…? There is no parameter or heuristic to compare the probable output out of all the labels from y1…
There is a saviour for us in terms of SOFTMAX
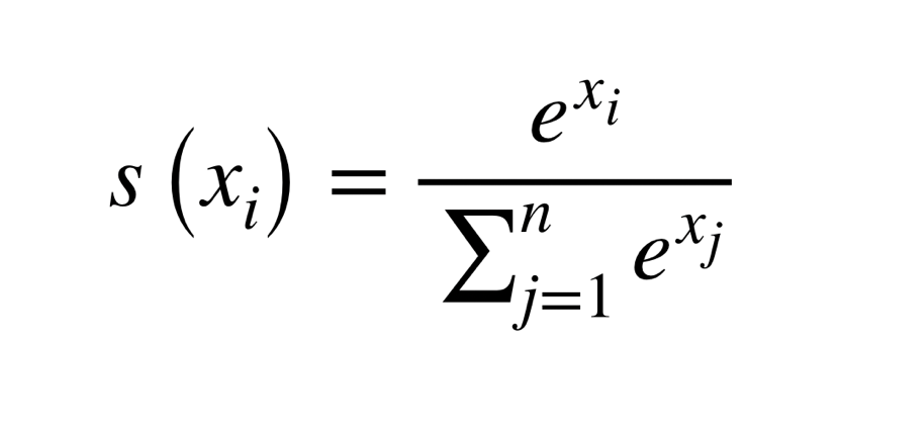
It is just a function that converts all labelled values in the range 0 to 1.
How does this help now?In a way of fact, they can be used as probability of occurrence of a character.
Similarly, as for y1 in t1, every output from rnn is stored from various times in some backend.
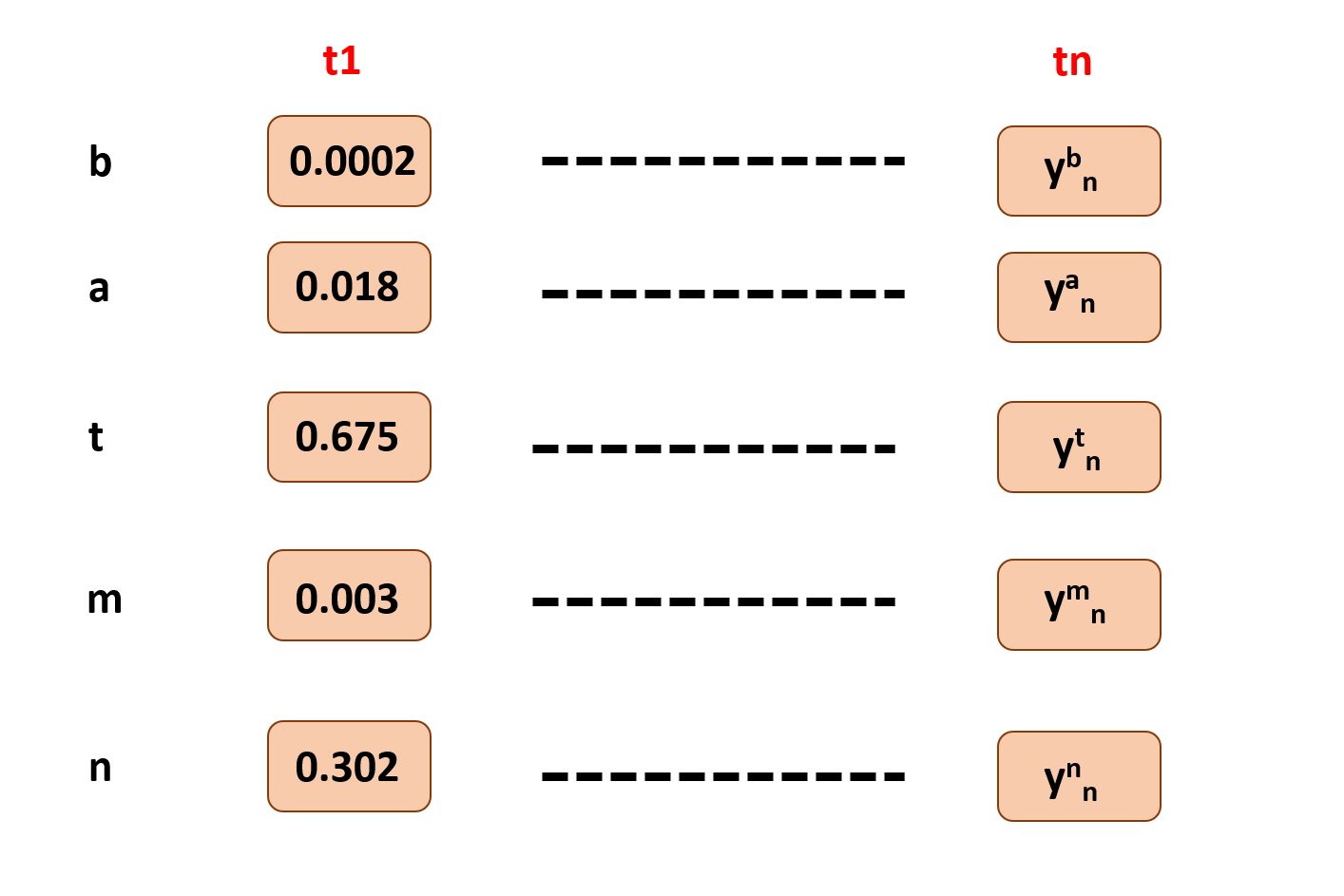

Okay, now we have got the arsenals in our hand, the nodes(probabilities) for all labels in different time steps.
What is our goal?
Align the sounds in text format, for simplicity we are using characters which are needed to be aligned.Though it is as easy as it sounds, there are many obstacles to reach the fortress. Let us face the obstacles one by one.
Firstly, let us just arrange the nodes in an order and see how it looks, for simplicity we will try to align just for batman
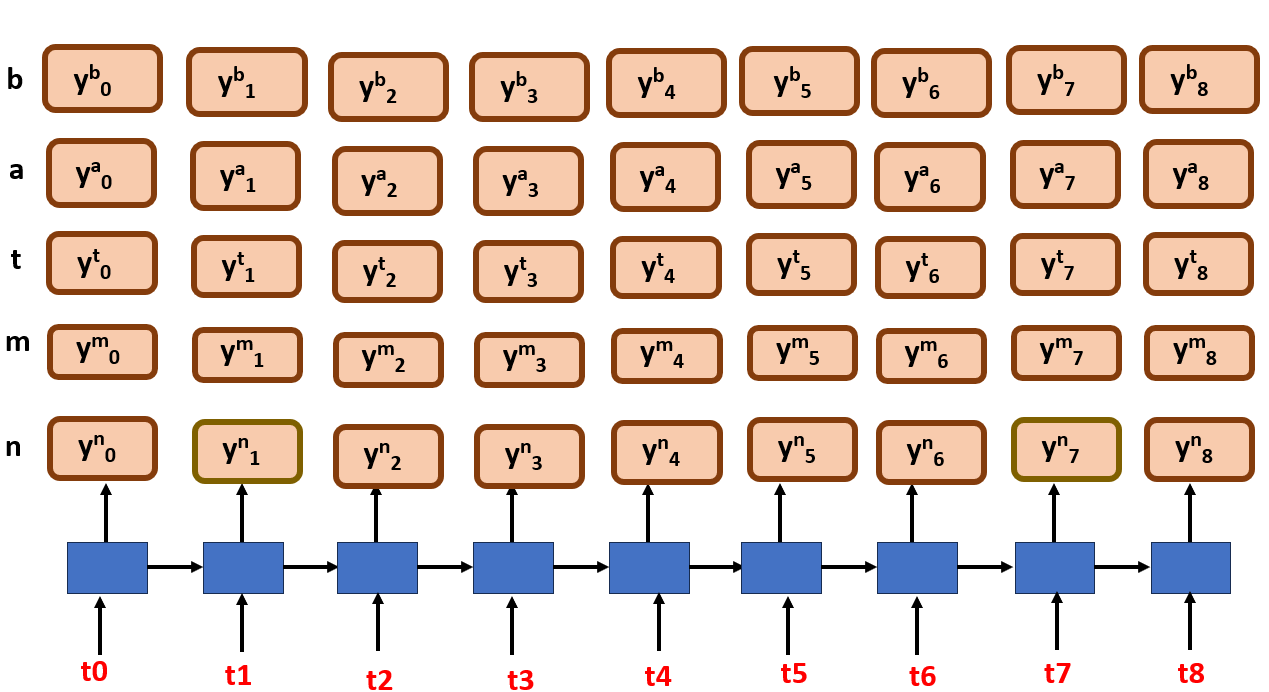
We know that, the sound of /b/ in batman or rather any other character can occupy more than one time step, as a single time step can be as small as 10ms, and people speak either slow or fast. Thus, the characters may repeat.
ok, now say we select the most probable label at each time step, and the output may look like this,
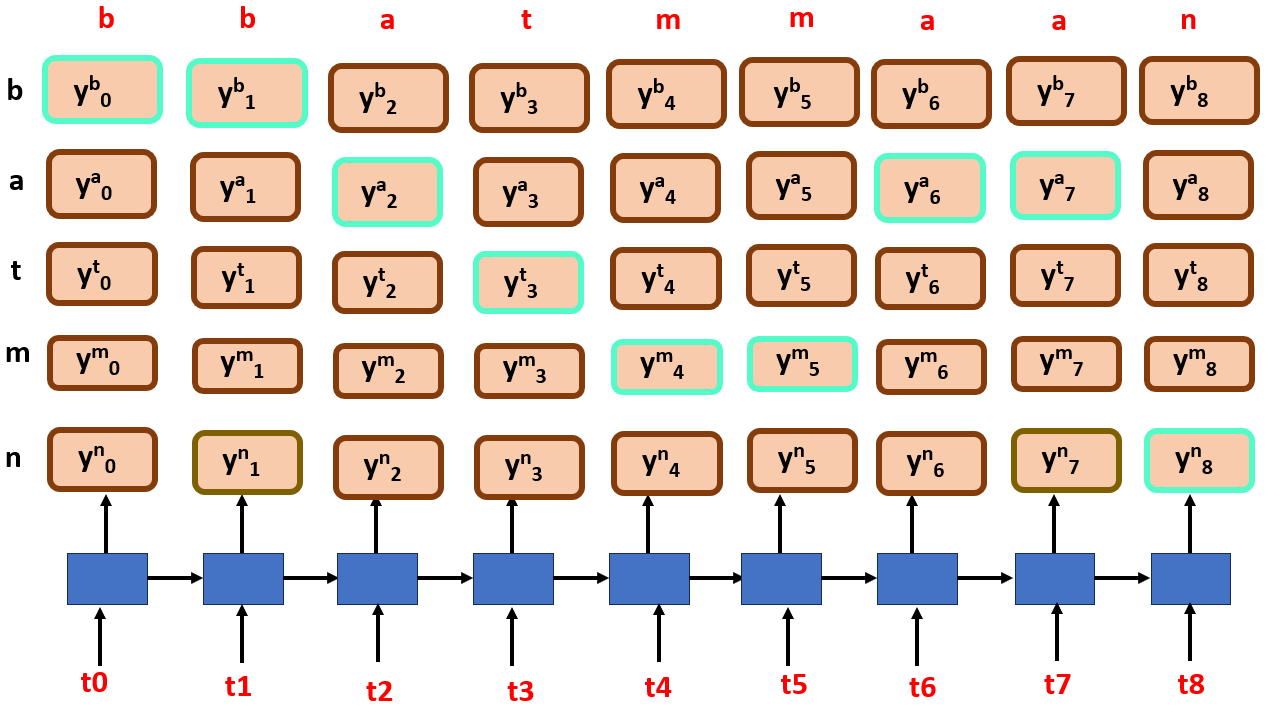
It returns a text of bbatmmaan!
How do we deal with the repeated characters? Simple, just merge them into one,
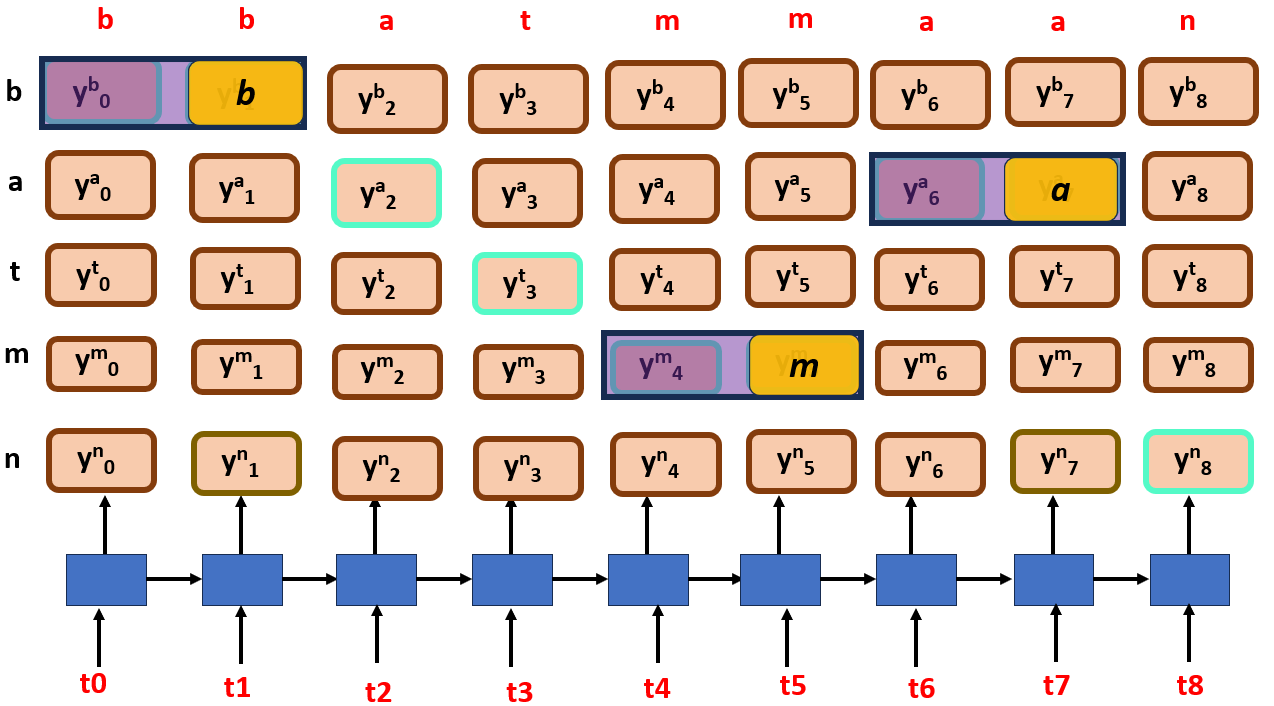
As we can see from the image, repeated characters are collapsed into one.We got the perfect text for what we have spoken, everything is great.
But life is not that simple, there are two problems in the fixture, let us figure out what they are,look the arrow directions from start to end,
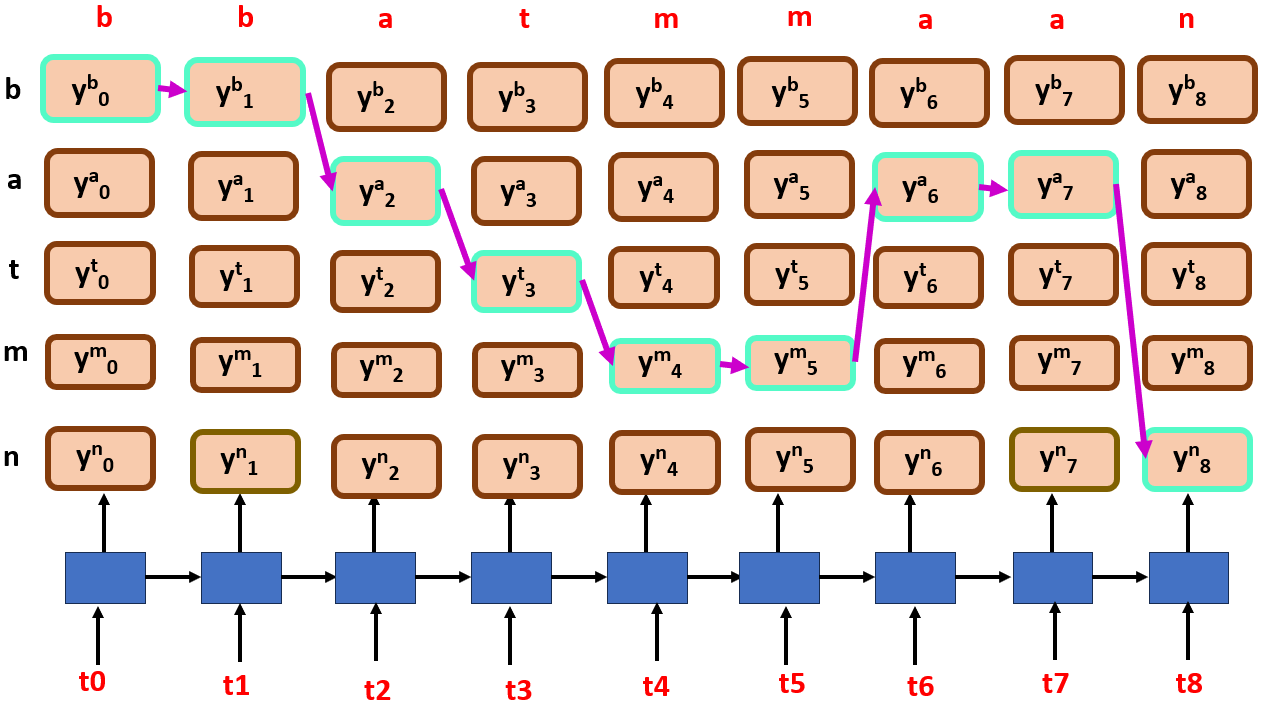
Did you find out the problem? Let me show you another example for target sequence of I am batman, focus on the edges this time…
The problem is in the path or alignment that it follows is it is not monotonic and it is ambiguous.And if the target sequence is long, it becomes a mess which also affects in computation, what should we do?
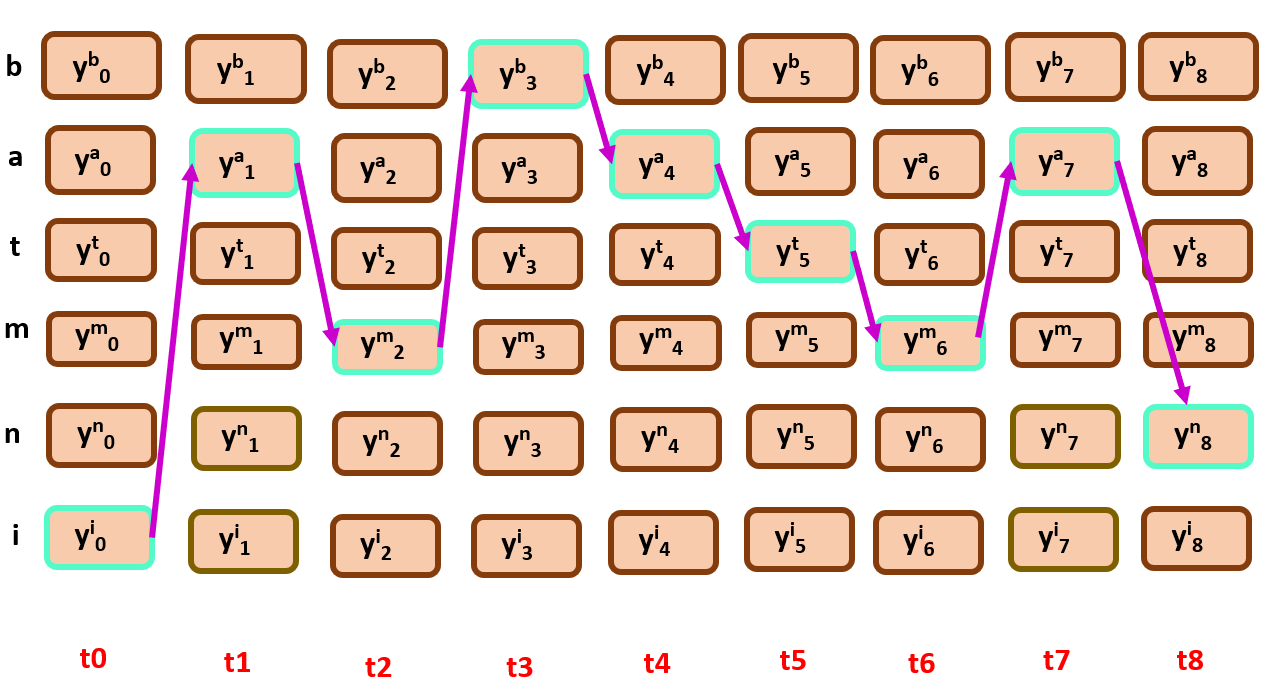
Given a target sequence, the nodes should be ‘constrained’, that is the order of the classification labels should be sorted in order of target sequence along with the repeated characters in the target sequence.
See the image below of how constraining the nodes will result us a monotonic order.
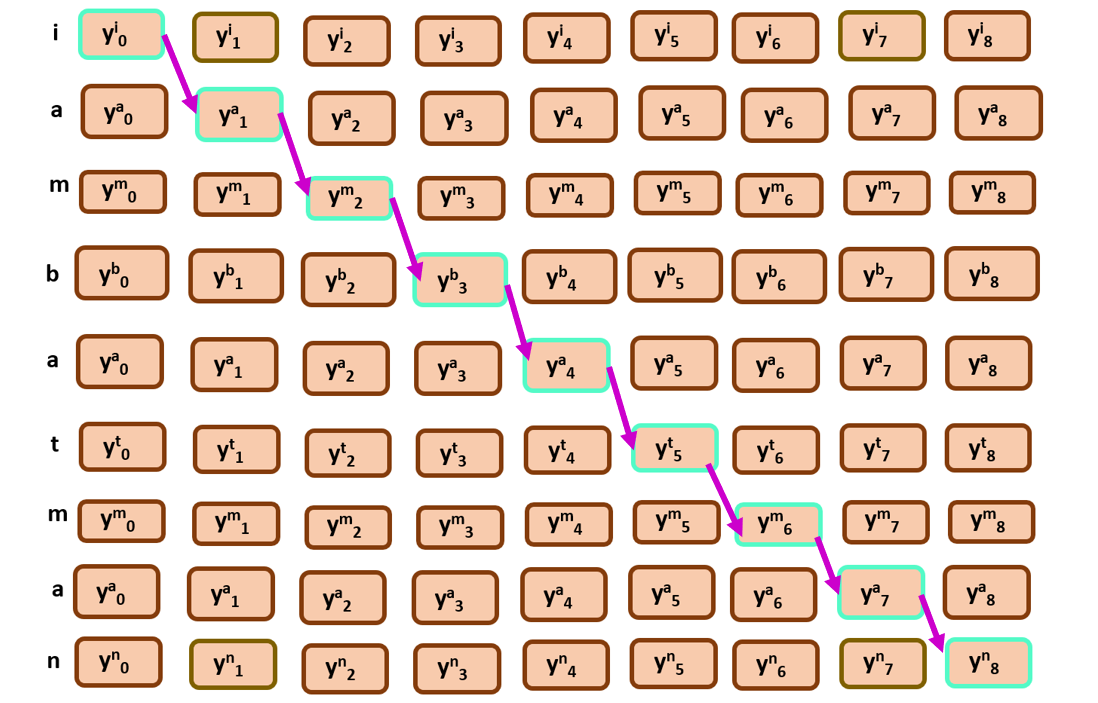
observe the edges…
![]()
Every time the alignment is starting from top left and ends at bottom right. This is important for future algorithm that we are going to discuss later.
One problem is sorted, what about the other problem, let me give you an example:
For the target sequence ‘pool’, what should my alignment be? How can I tackle the repeated characters without merging them.
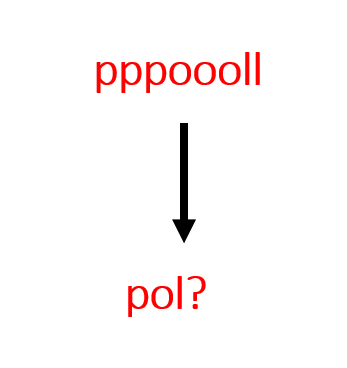
There is good solution for it, use a blank symbol, generally represented with ‘ε’. How does it affect?
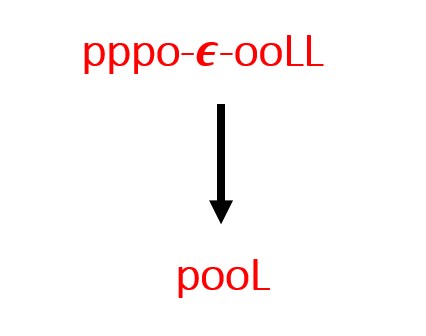
It is working great, let us see it with the alignment too,
Output text = pϵooϵooϵl –> pool
Nice! We have bypassed with repeated character issue and as well as the lack of monotonicity.
Now, let us find out how CTC model is trained, There are two issues with it again…
Say, only output sequence is provided for training data, no timing information for each label is provided, in this scenario how can we know when to output the symbols, and if some symbols are returned in output how do we know that they are real?
We will get into this later, but suppose we got to know what are the real outputs for a sequence at every given time step, how do we train that model, specifically how is backpropagation done?
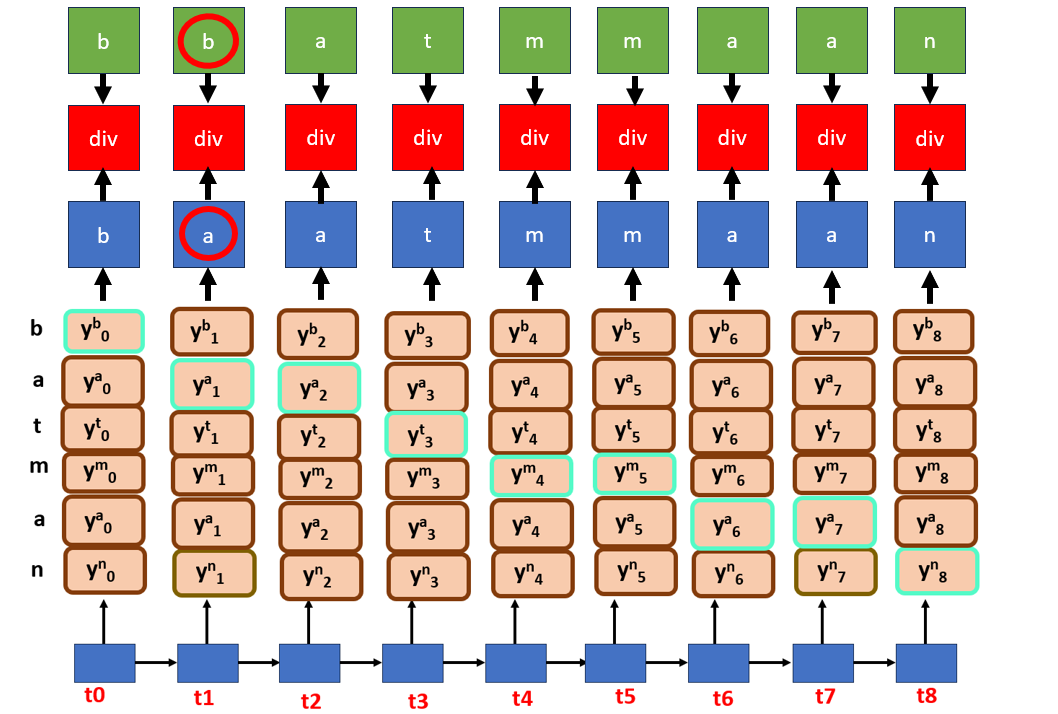
For CTC, the divergence is calculated between the ground truth labels and output generated by the model(prediction).

Xent -> cross entropy loss function
Generally, a loss function is something that tells the difference between wrong and right label. It doesn’t specifically give where the mistakes are, but it tells how closer or farther your predicted labels compared to real labels.
Cross entropy: It can also be called as logarithmic loss. It measures the performance of classification model (predicted characters in our case). The output of a cross entropy is always between 0 and 1, The lesser the good.
The cross entropy increases if the difference between the predicted and actual probability is more.
the total divergence can now be calculated by adding all cross entropies loss from every time step.

Say, if the model didn’t output the sequence accurately, we have to change the weights in the rnn. We use a term ‘gradient’ which is the amount of change (addition or subtraction) to modify original weights. At every time step t, corresponding divergence value is used as a gradient to update their weights.
The total is calculated from every time step’s divergence, to the see the model performance.
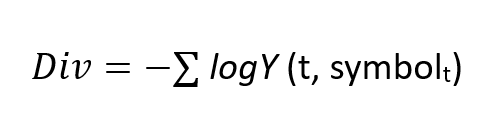
In the above formula I just used the cross-entropy function to use in divergence.
For gradient we differentiate the divergence for every time step t, so except the tth term, every other time step’s gradient will be zero.
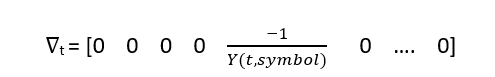
Cool, we know how the backpropagation is done for CTC using divergence as a gradient.
Now we will be going into the heart of CTC, how can we handle alignments if we only know the output sequence with no timing information provided. How can the model accurately align with the output sequence?
Well, there are three methods
- Randomly guess the alignment with some heuristic
- Viterbi algorithm
- Backward forward algorithm
But before that let me be clear with two terms
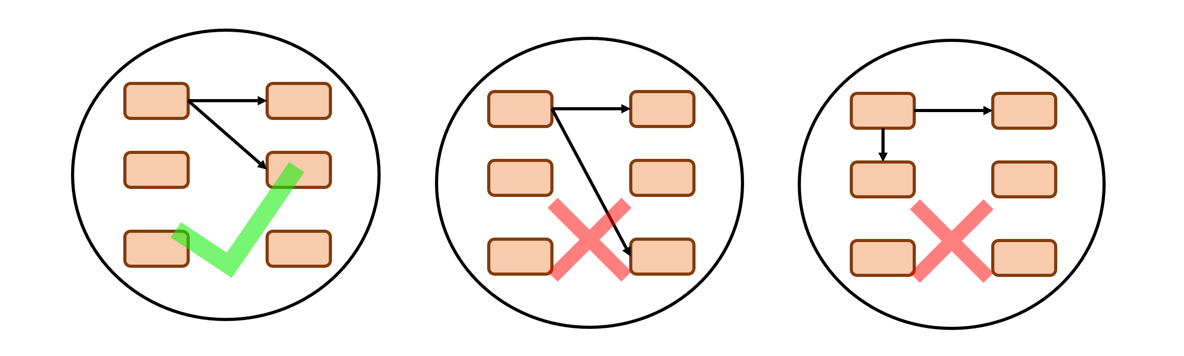
- Monotonicity:
Nothing but, something that is going in a single direction. And I hope the reason for it was pretty clear from the discussion earlier.To maintain monotonicity and less ambiguity we constrain the paths to go only to its immediate next node or the one that is below it.
- Path Score
We need to have something to compare for the best alignment among all the paths that lead destination.
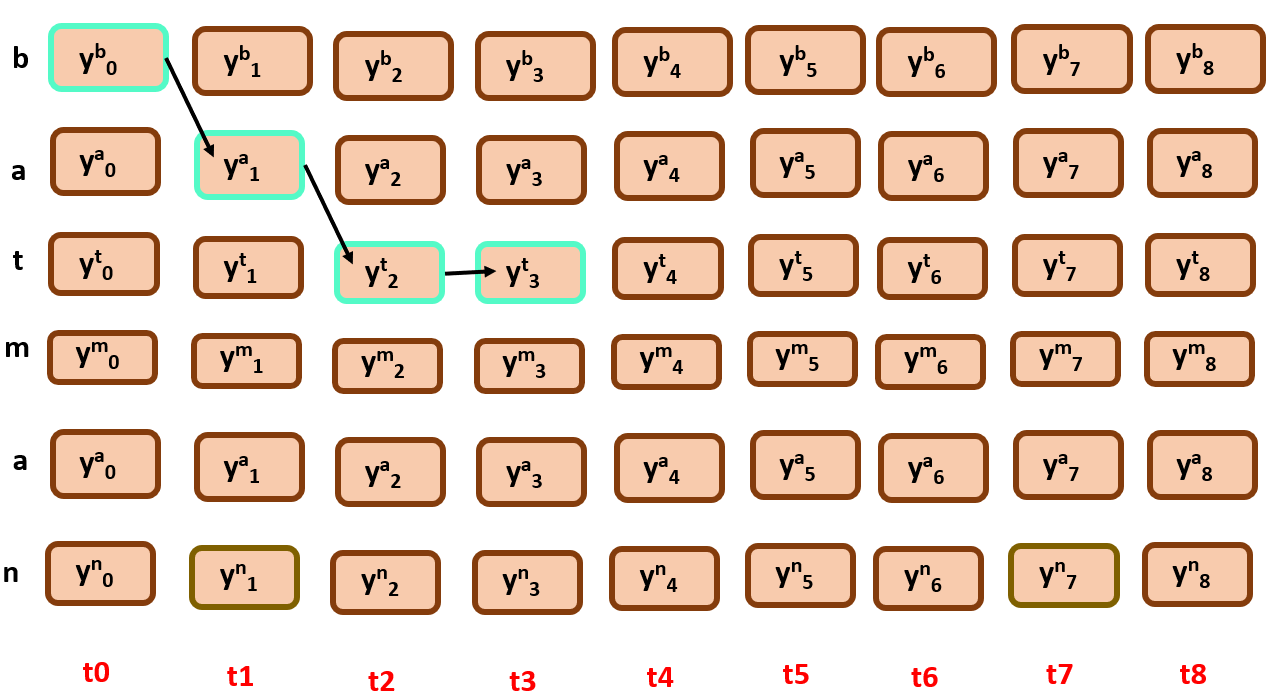
The path score here is the product of all the nodes that the alignment is traced with.

Similarly,
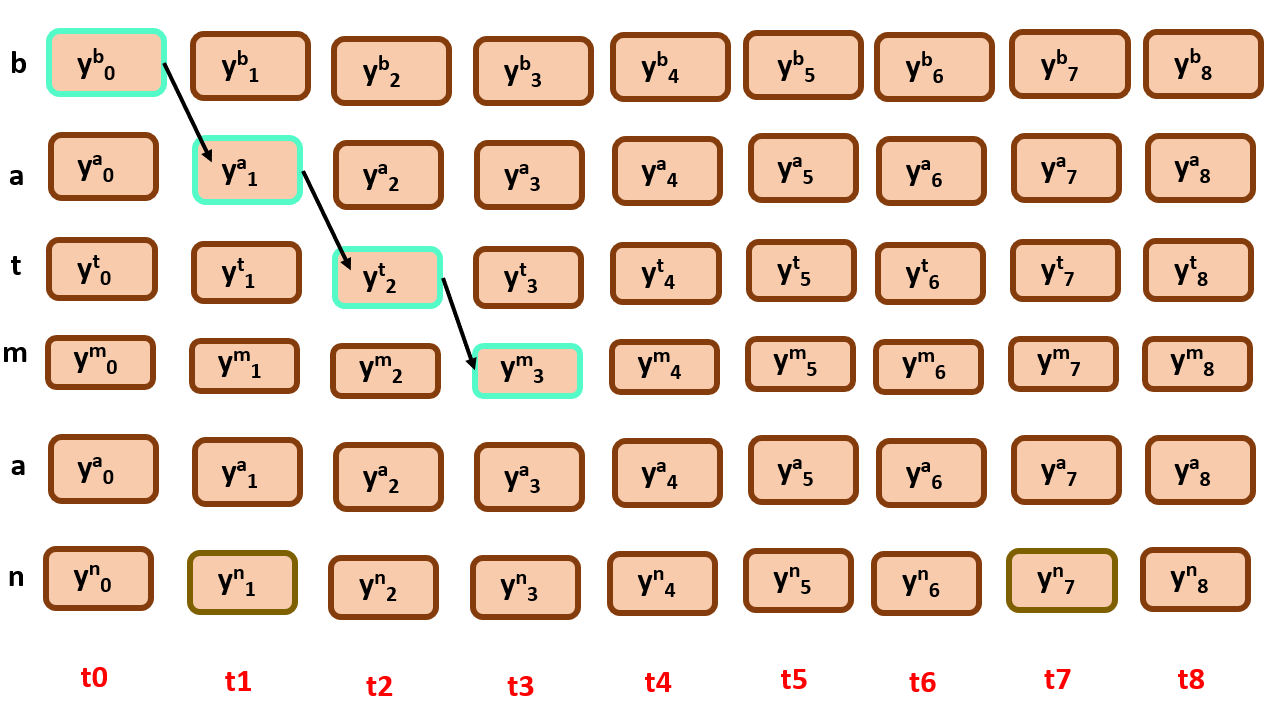
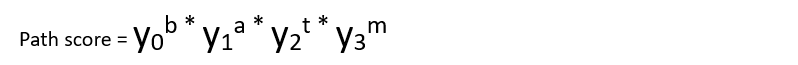
simply these are the following possible paths by following monotonicity and constraining…
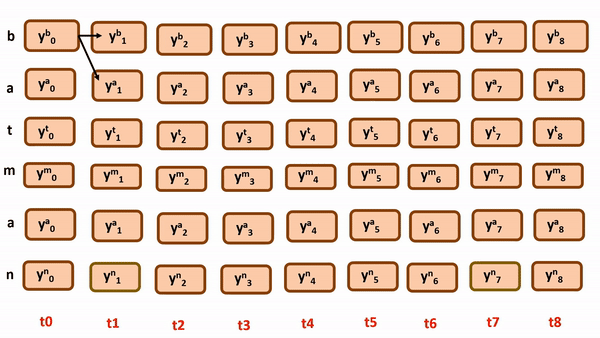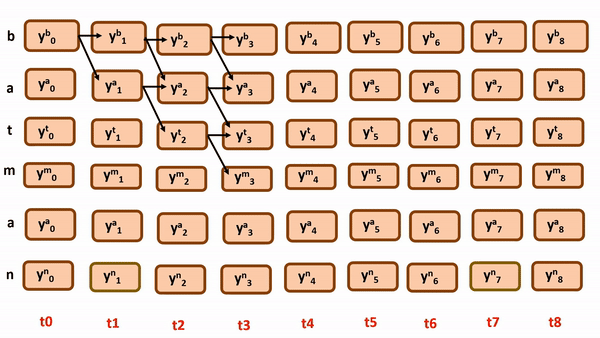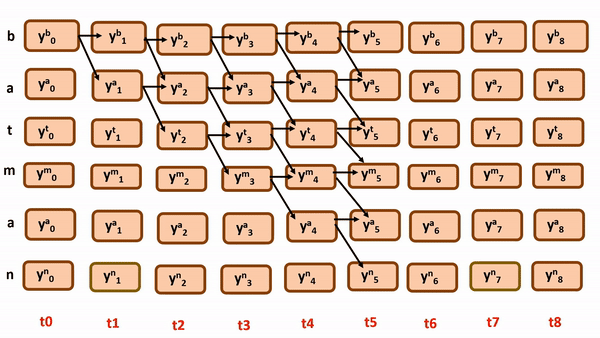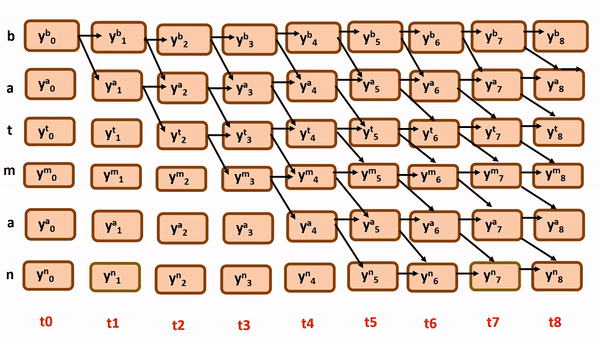
Do you think there’s some mistake here? Can we achieve full monotonicity with every possible path from the above illustration?
Check this instance…
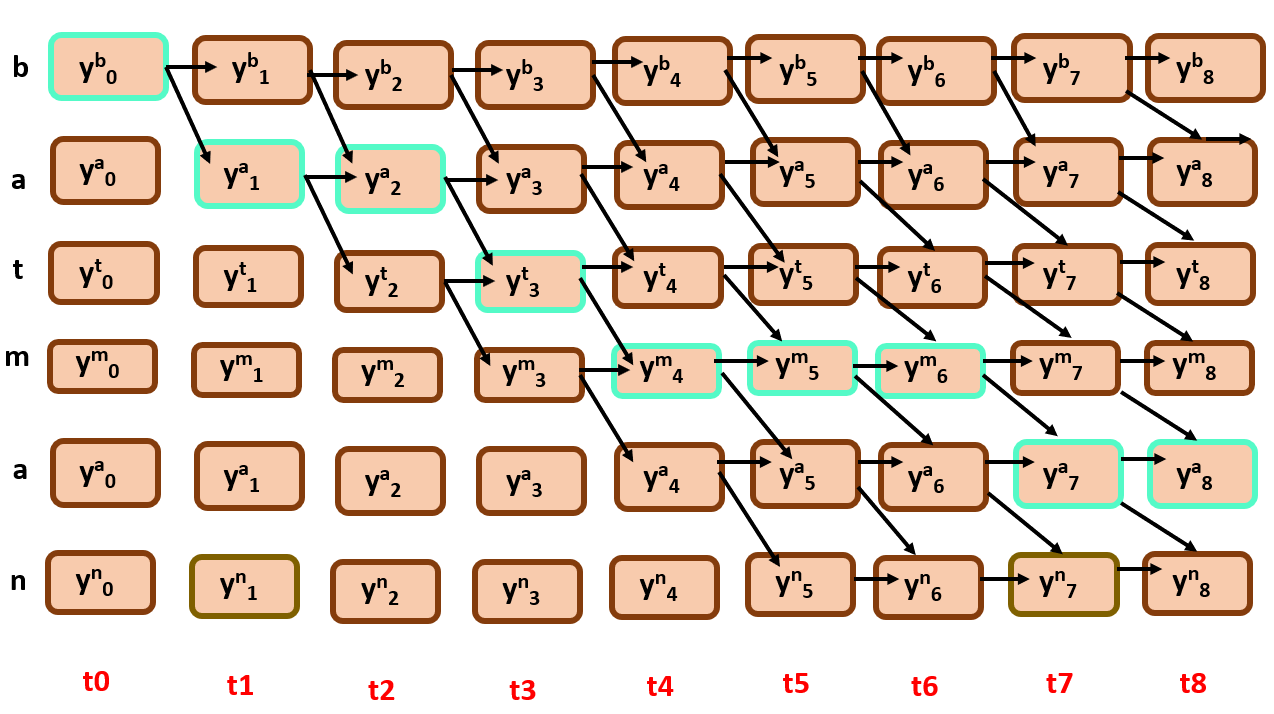
Though it followed the constraints, it still did not achieve the full target text, why so?
It is because we should also constrain the nodes from backwards too, that is the path should must end at bottom right.
Let us now constrain that too…Initially, we block all the nodes except the end node in the last time step.
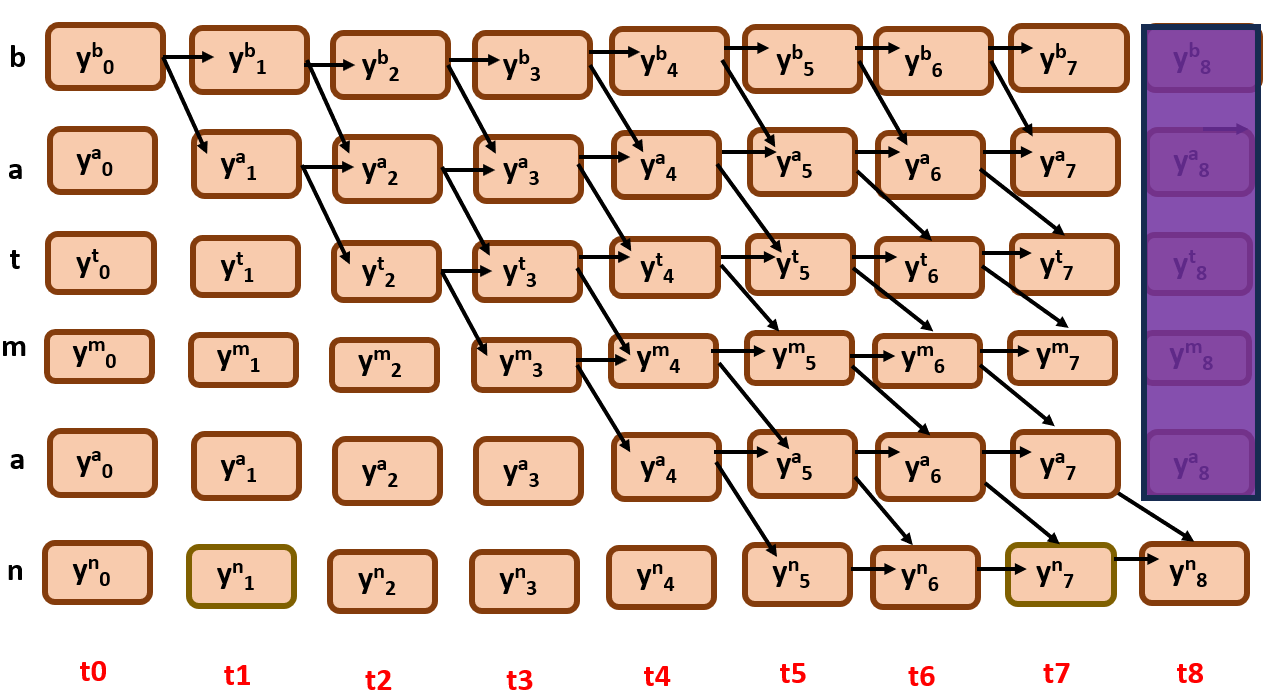
You see what I did here, I similarly had blocked the nodes that are not required by iterating, for every previous time steps (only the nodes where feasible paths are possible are kept).
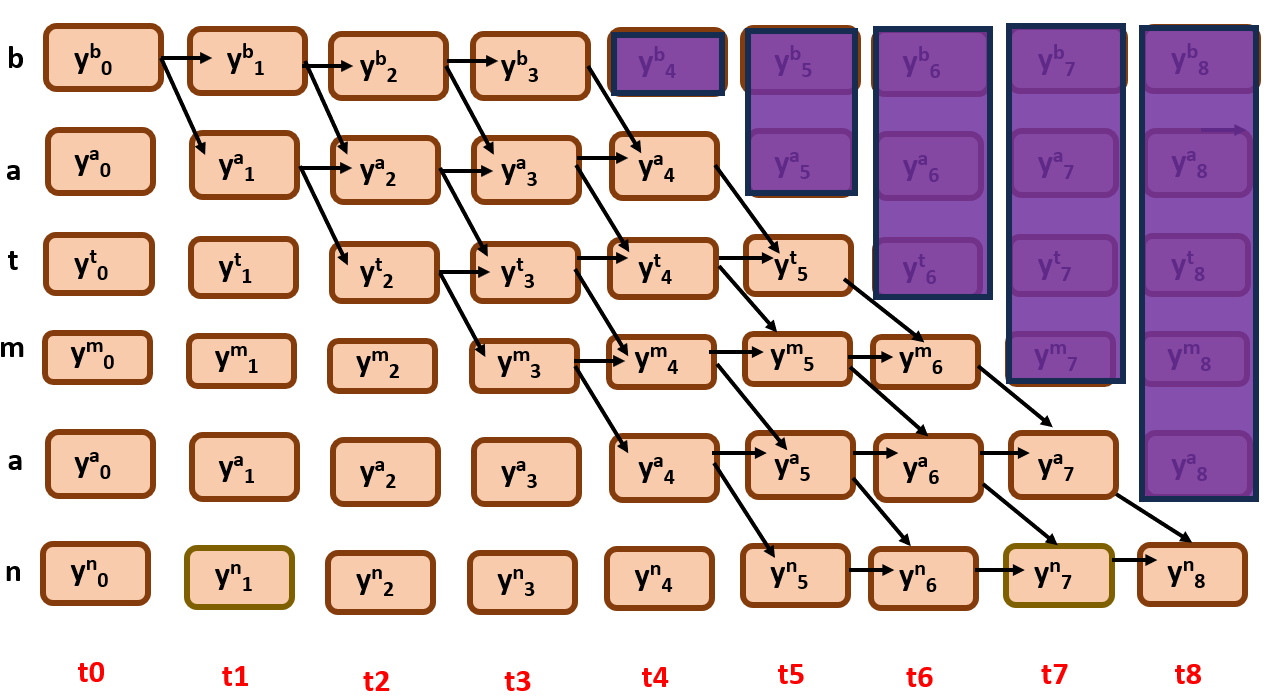
Let us go deeper into CTC now,
1) Randomly estimating path:
It Is as simple as it sounds, by following some reasonable heuristic or randomly assigning the paths is the first step. Once a path is assigned, the model checks for the divergence and the gradient is returned back to change the original weights.
This sounds so simple, isn’t it? That’s the trap, though it may perform well only for training data, it may become less reliable for real time data (which is mostly different from trained data)
let us find an another alternative
2) Viterbi algorithm:
Generally, Viterbi is a dynamic programming algorithm which is used for obtaining the maximum probability in a sequence of hidden states, it does this simply by solving the sub problems (core of dynamic programming). What are the sub problems in our quest to find the best alignment? It is to choose the highest probable path until the time step t by reviewing the previous parent nodes.
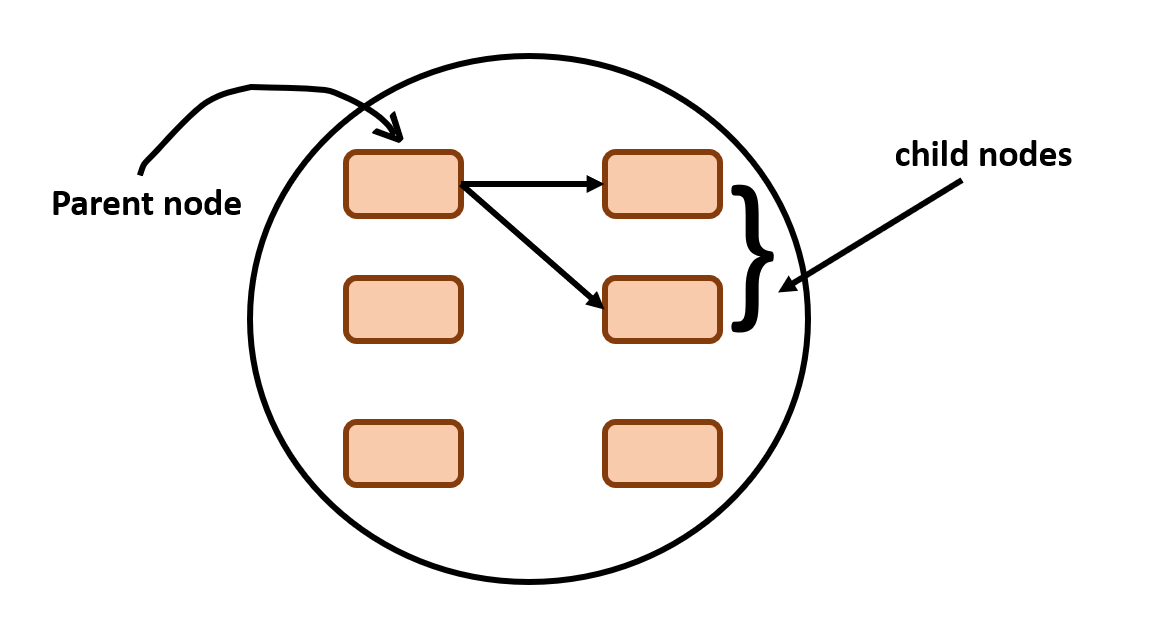
In a sense, we know that the best path (maximum probability path) must be an extension to one its parent nodes.
Some Rules:
- If there is single incoming edge to a node just consider it as possible path
- If there are two incoming edges competing for a single node, choose the best parent of one of them.
As usual, let us understand it more visually,
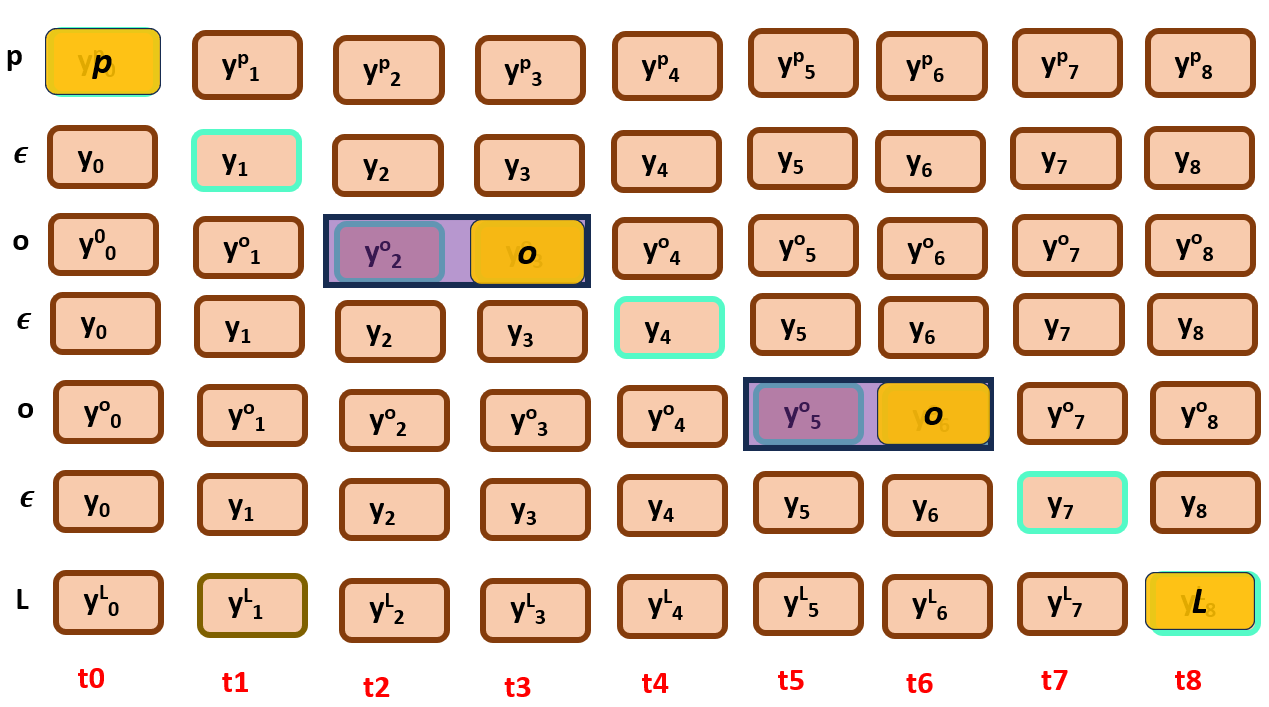
Initialization
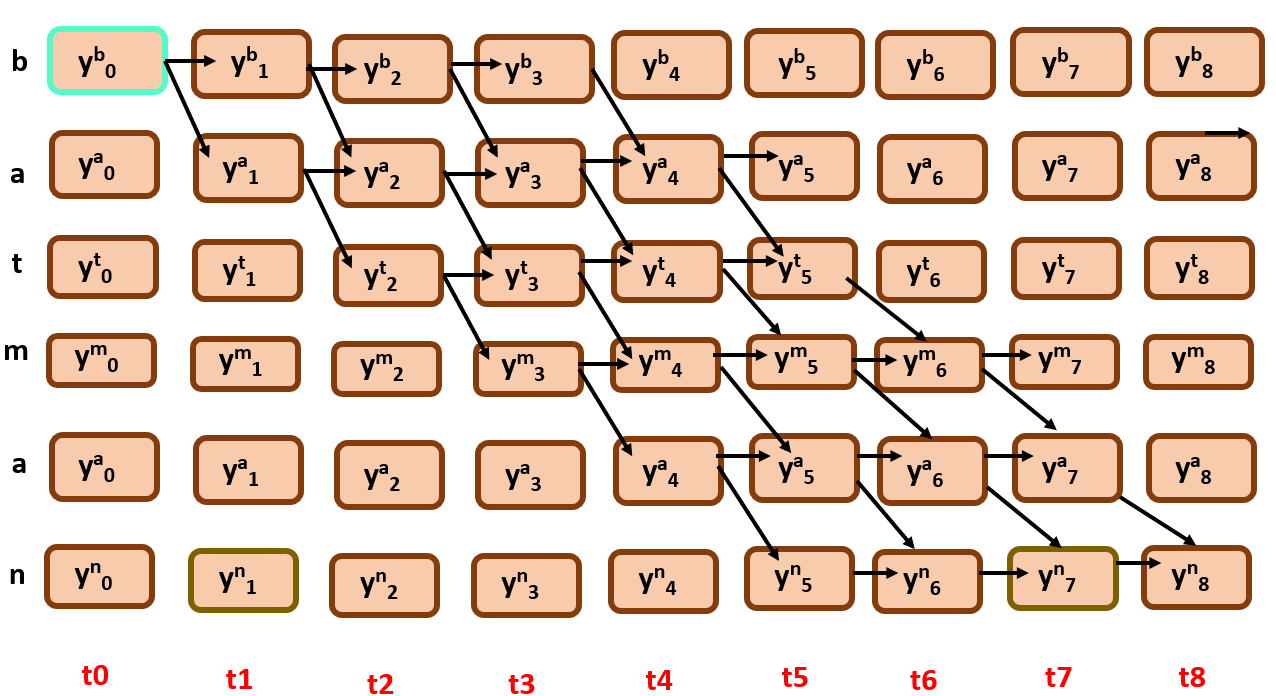
Here, as constrained we initialize with top left node i.e., yb0.
There is no previous node, hence no parent node, BP(t=0,r=0) = None
where t belongs to [0, T] and r belongs to [0, len(classification_labels)-1]
Best score or Bscr(0,0) = yb0
Now for time step t1:
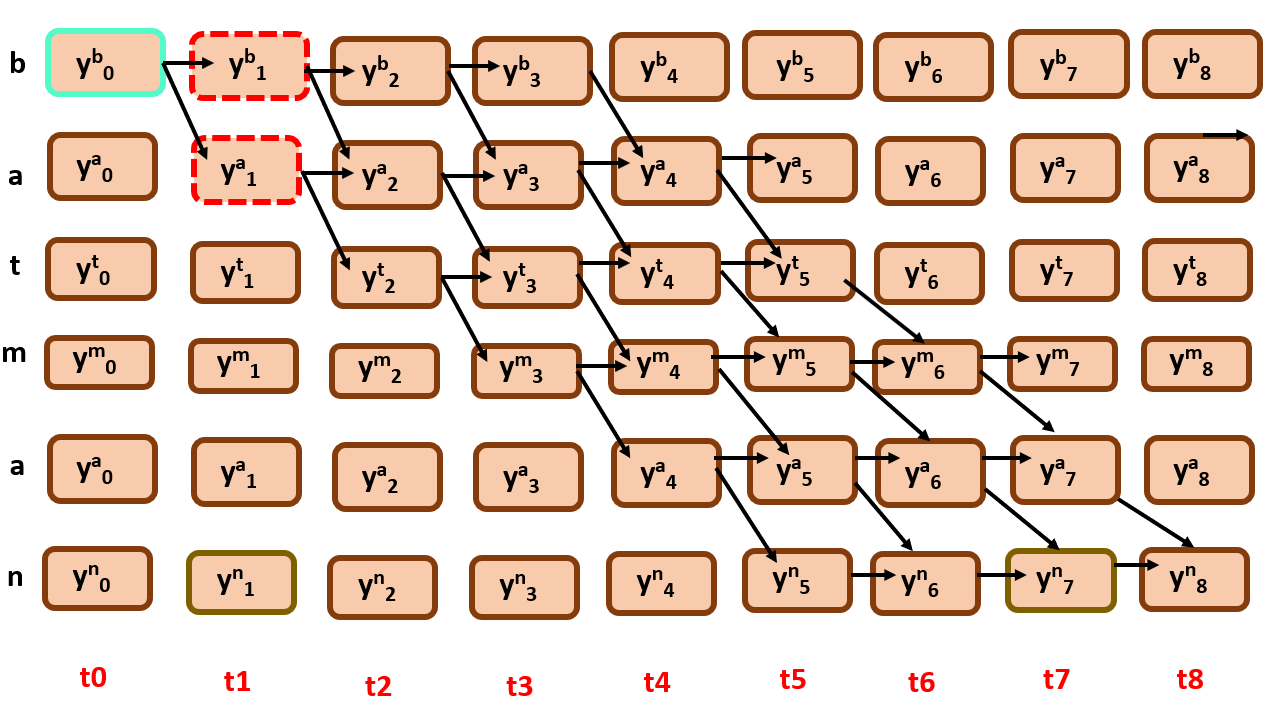

so far so good,

Here we have to choose the best parent among them by following criteria,
BP(t,r) = r-1 if Bscr(t-1,r-1)> Bscr(t-1,r) else BP(t,r) = r
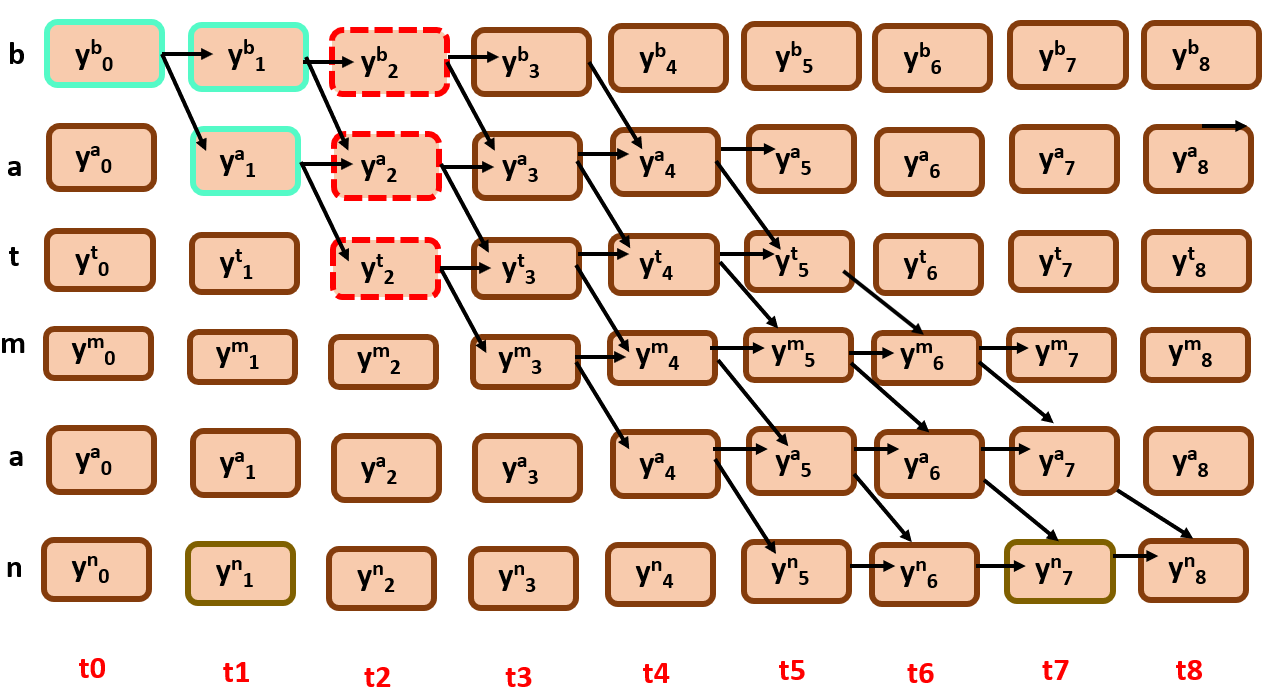
Once we get the best parent of the two nodes, Bscr is calculated with it…
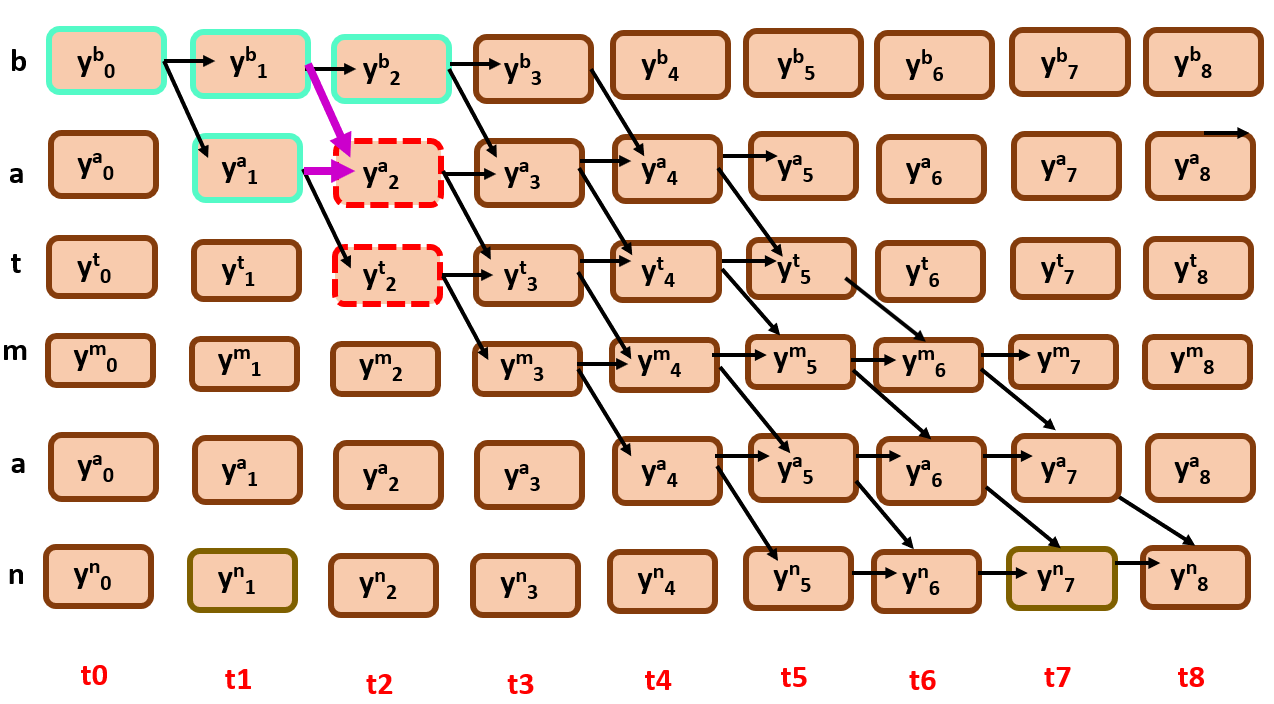


Well, you got the process right…
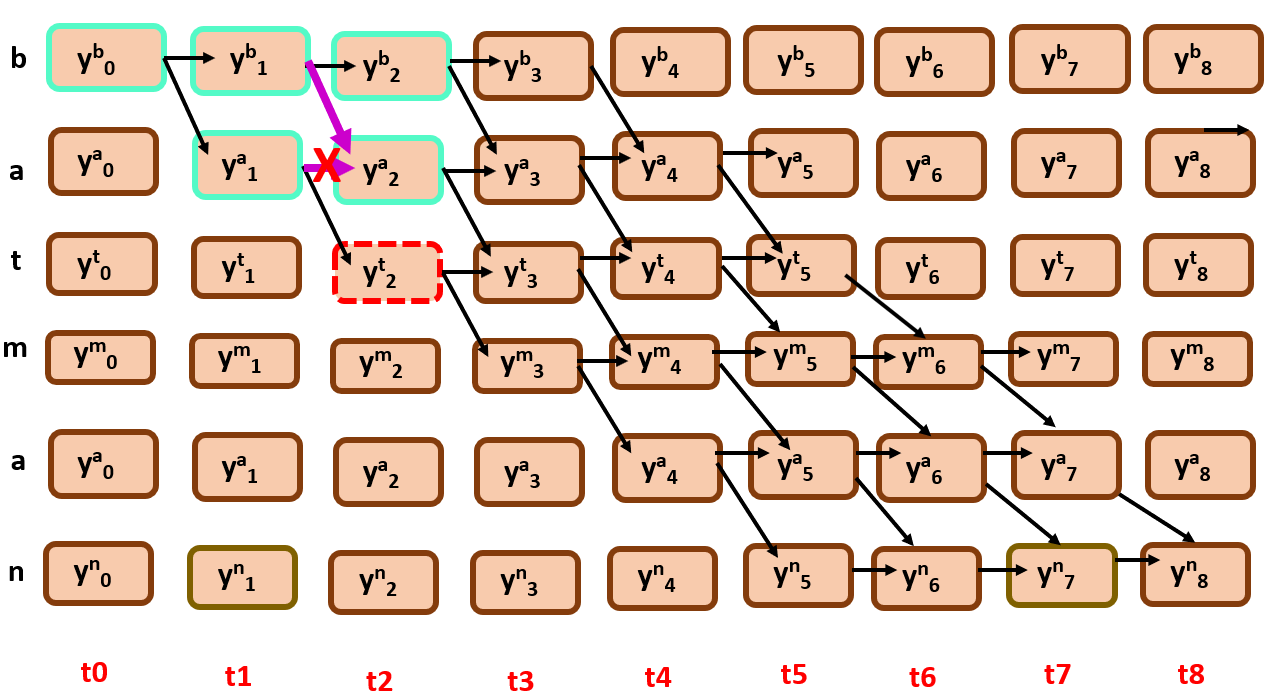
And then, we simply back track from the end node to the start node as shown below,
What’s next?
Yes, after we predict a sequence, we have to compare it with the actual transcript, and backpropagate using the gradient that is calculated with help of divergence.Everything is great, but what’s the problem here?
Here, we are sticking to an alignment without considering all the possibilities, it leads to poor local optima. That is, it will not perform well for unseen data, as it is heavily dependent on initial alignment
To avoid this, we are going with the expectations. It simply considers all the possibilities of an event by averaging over all the alignments
If you want to understand it further, you can checkout some youtube videos…
Check here: Expectations
Expectation by statquest
So, we need an approach that considers all possible alignments,I will try my best to not go deeper into the math behind it, and try to cover the major portion with visualizations, if we you are interested, try seeing CTC published paper
What is our motto now? To find the probability of all the possible alignments in the graph for a target sequence S that go through a node yS(r)t
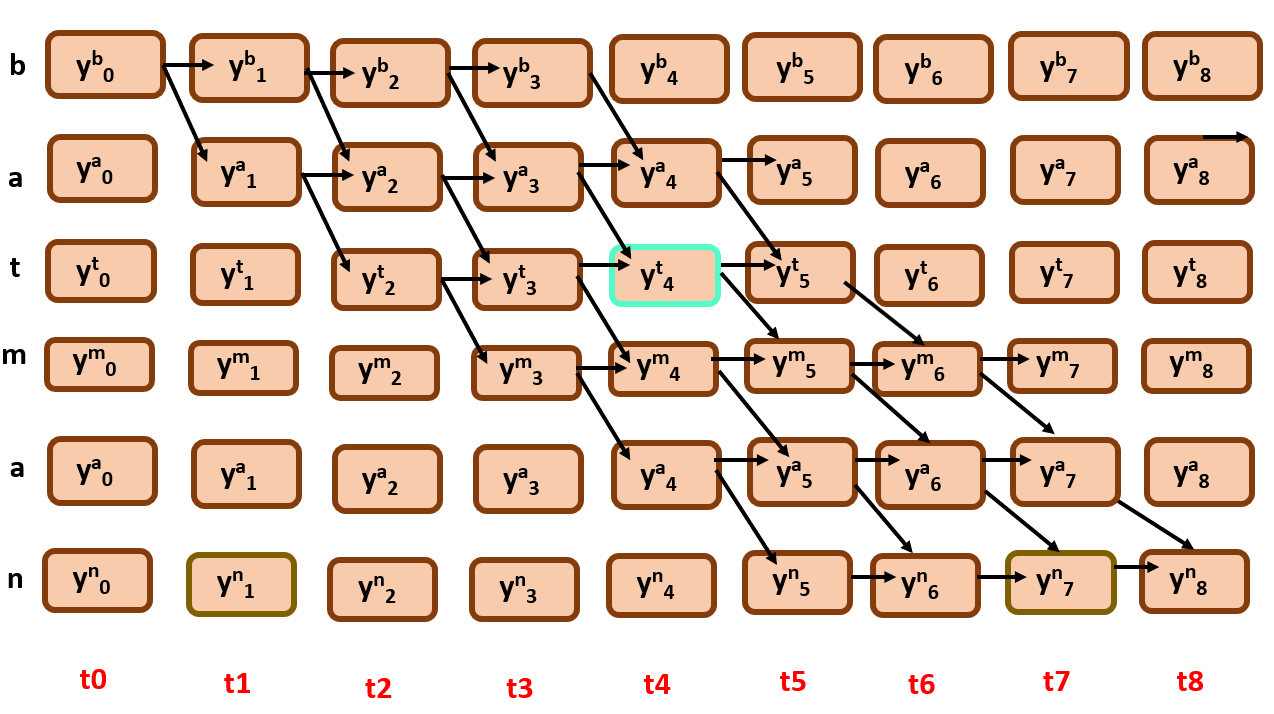
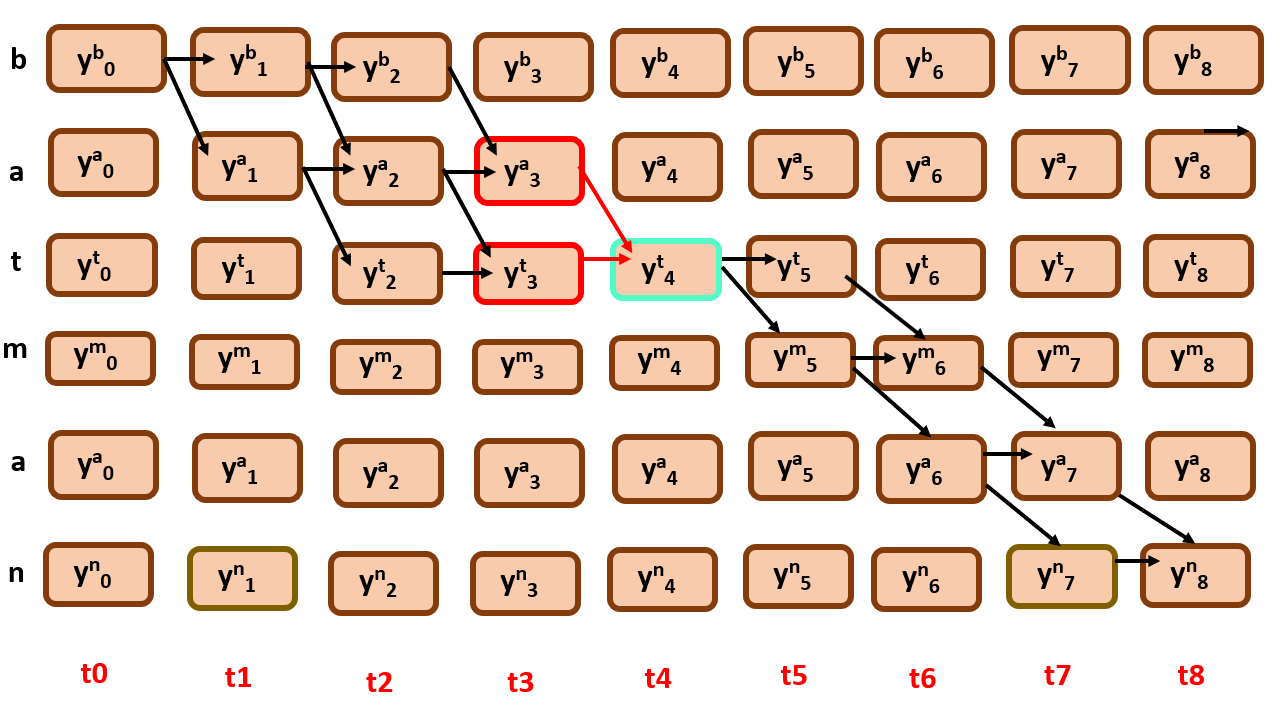
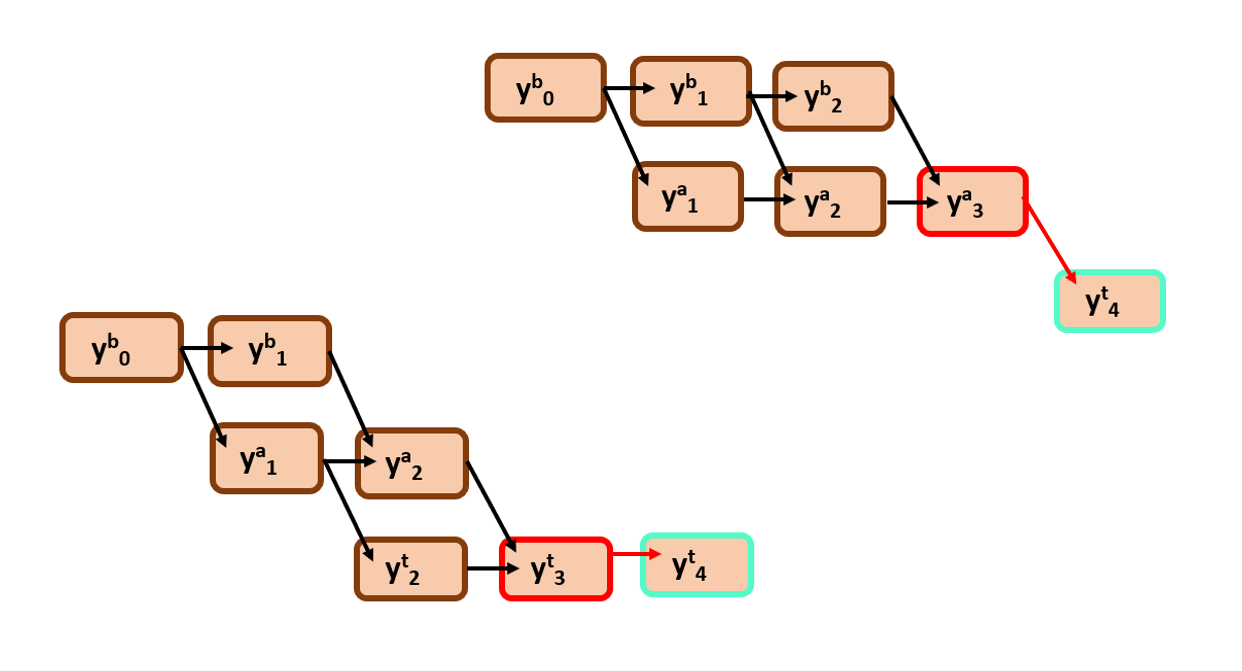
say for suppose I want to find the probability of all the possible alignments that pass through y4t, we only need to consider the edges that involve this node
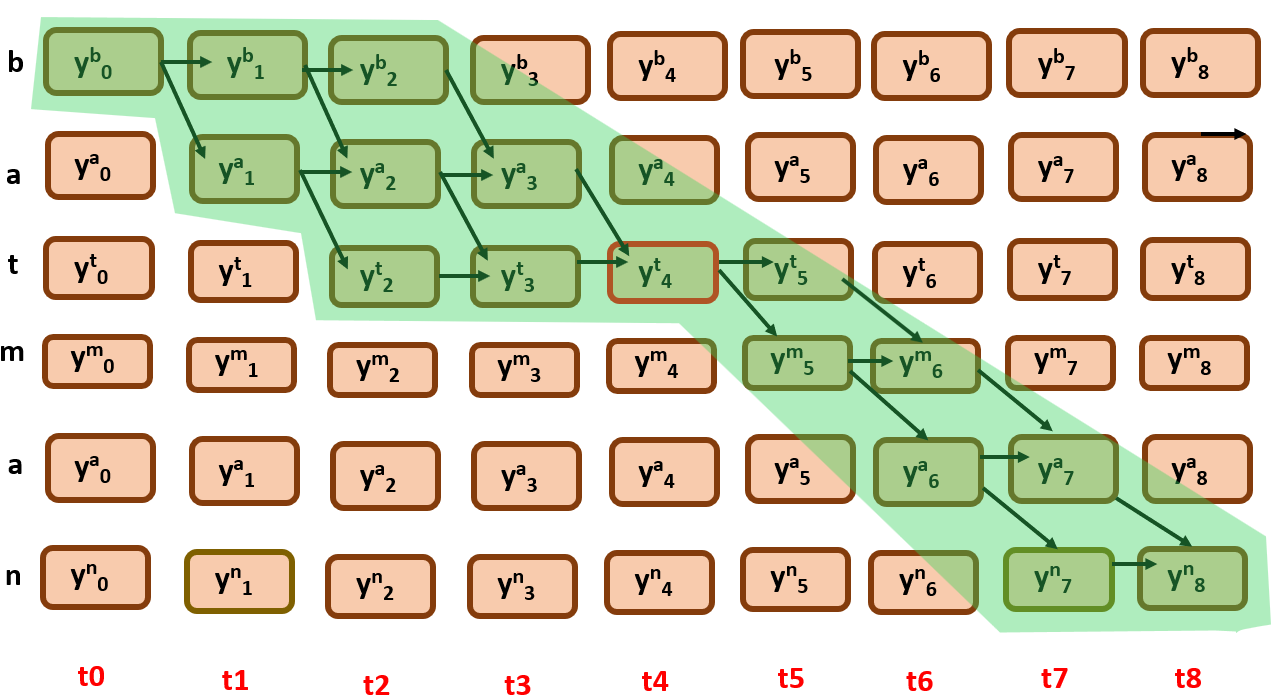
As you can see the green portion here, it is region of interest, the possible alignments that are passing through the required node. Now how can we find the overall probability of the green subgraph?
Here comes the forward and backward algorithm approach, the green subgraph that you see above can be divided into two further sub graphs.
3) Forward-Backward Algorithm:
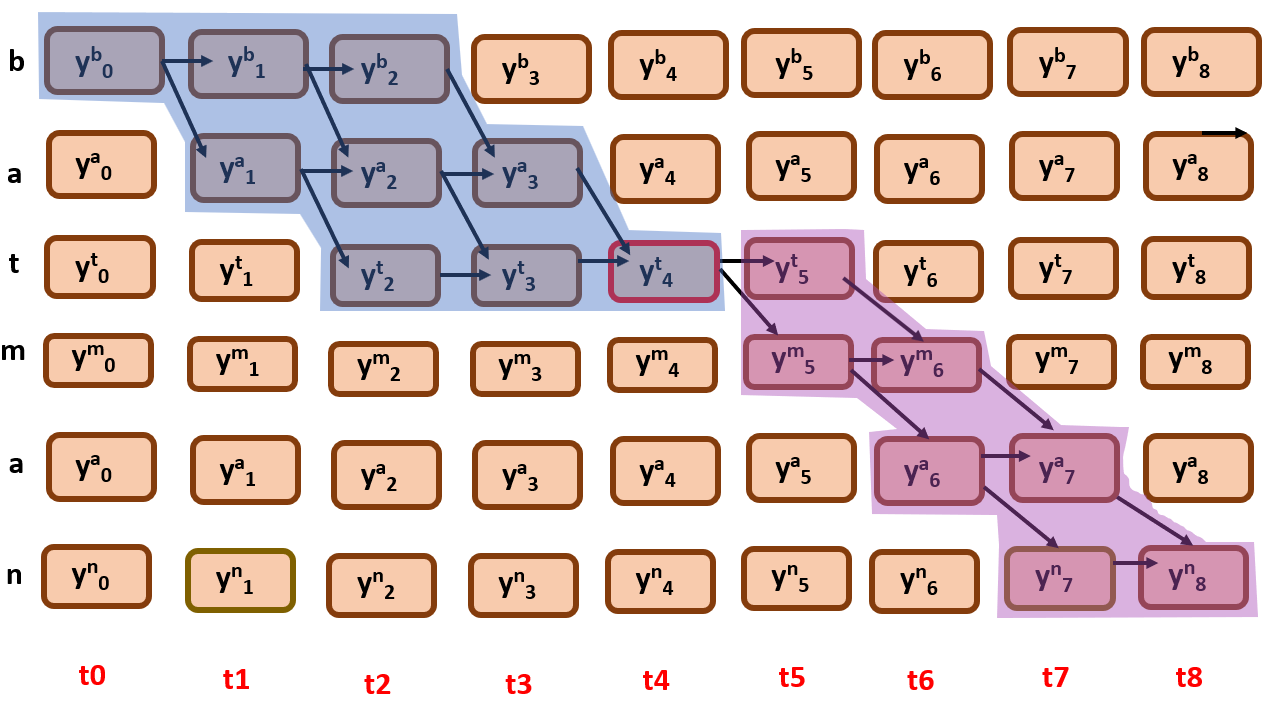
the blue one here is forward probability, and the purple one is backward probability.Let us calculate the forward probability first,
- Forward Algorithm:
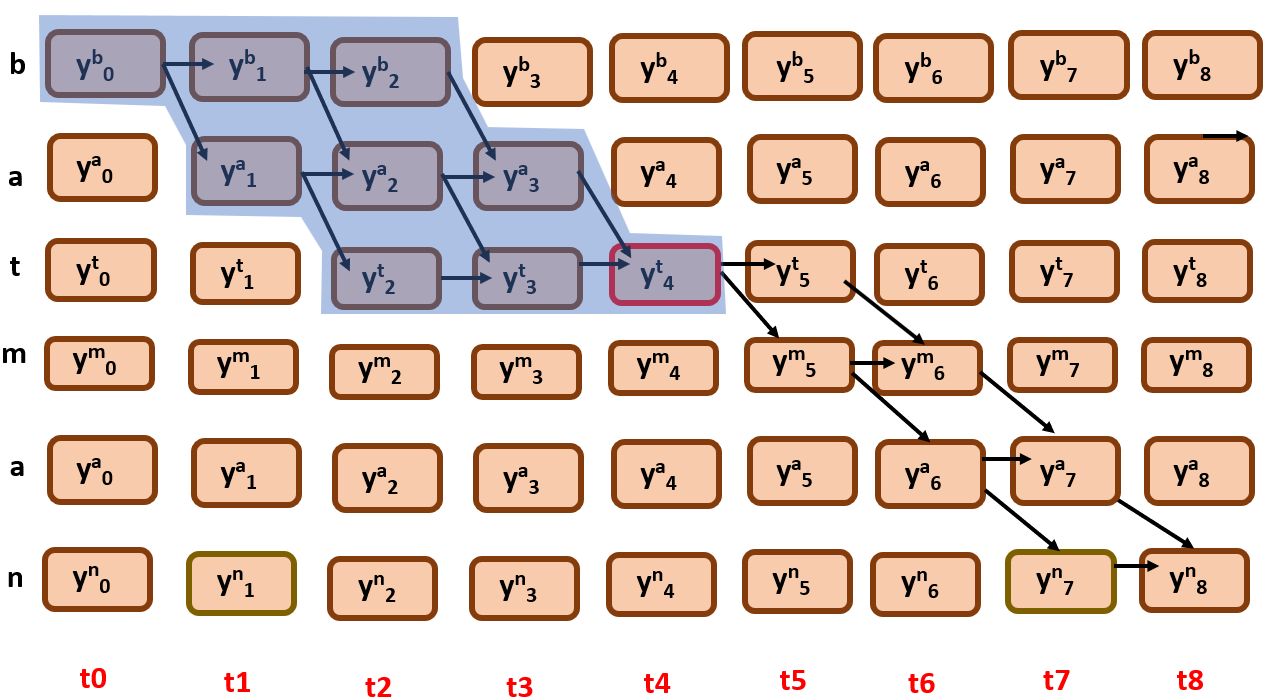
What is the first thing you notice? All the nodes in forward probability are incoming nodes to y4t
Take an instance,
α –> denotes the forward probability
we have to find out α(t=4, r=2). So, there are two parents, y3a and y3t. We know there is an equal probability of choosing either of them.
α(t=4, r=2) = Prob(sub graph ending at (t=3,r=2))y3t + Prob(sub graph ending at (t=3,r=1))y3a
it can also be represented as
α(t=4, r=2) = α(t=3,r=2)* y3t + α(t=3,r=1)* y3a
the generalized form can be written as,
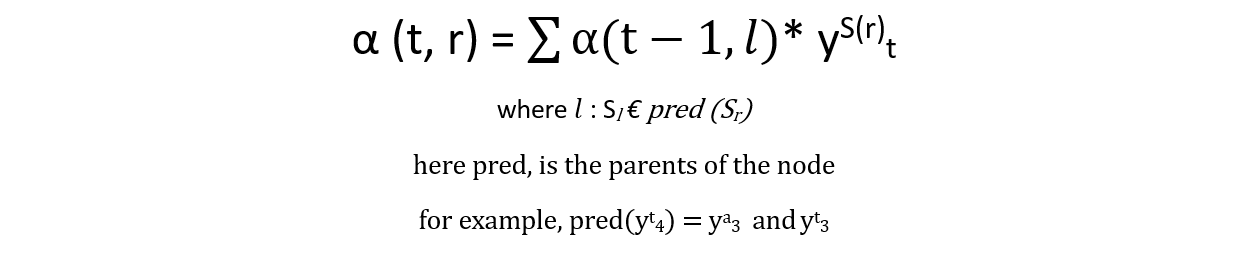
generally, we will use this recursion, for all the time steps, so that it can be flexible to calculate for finding the forward probability of all possible alignments passing through any particular node
Initialization: α(t=0, r=0) = y0S(0) i.e. y0a and for other nodes r>1, α(t=0,r>1) = 0
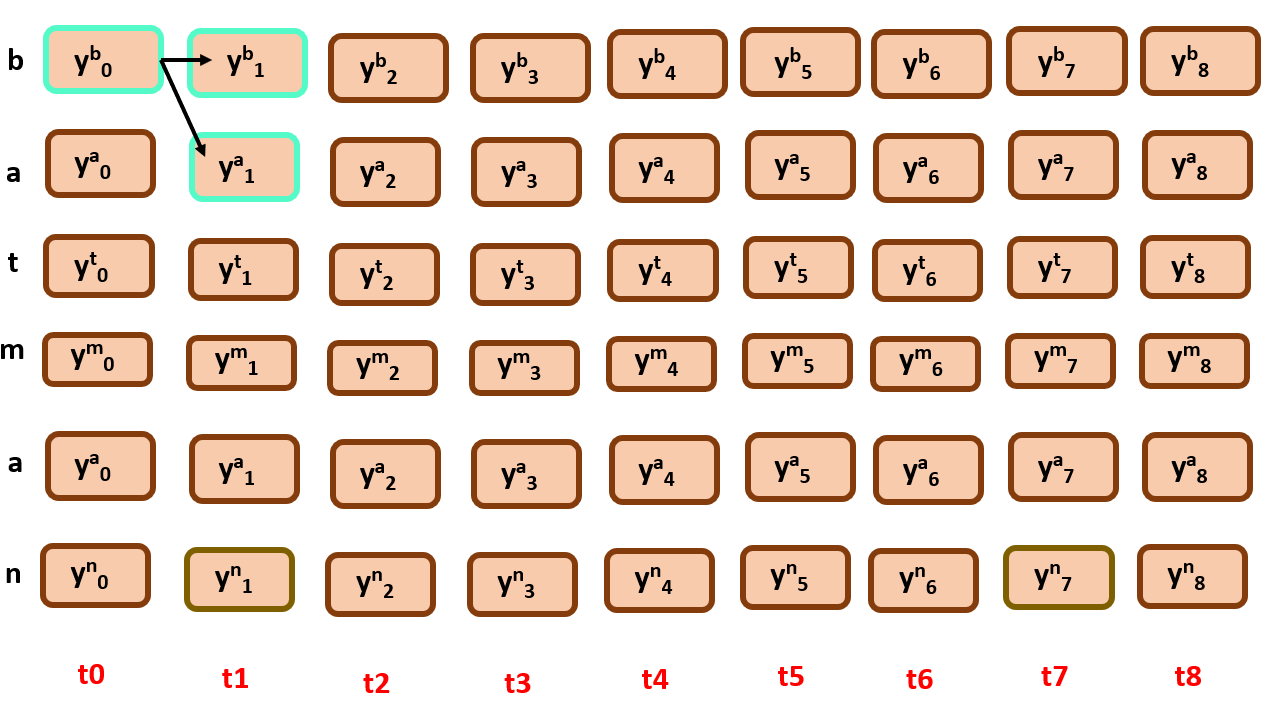
For t >=1 :
We will use the recursive function we have defined above,
α(t=1, r=0) = α(t-1,r)*yS(r)t
and we continue this until the last time step,
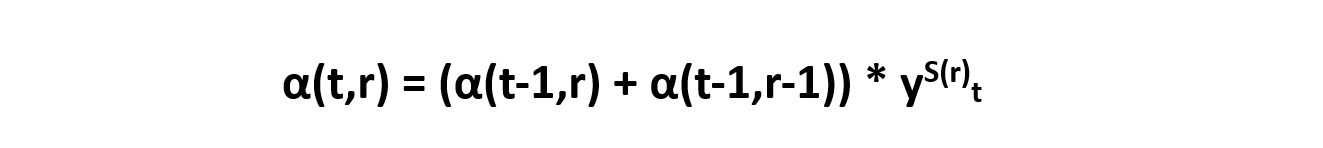
In this way, we will add all the possible alignment probabilities to have a global scope.But there is a problem here, all the probability values are less than 1, which inevitably causes an underflow, to avoid this we convert formula into log form.
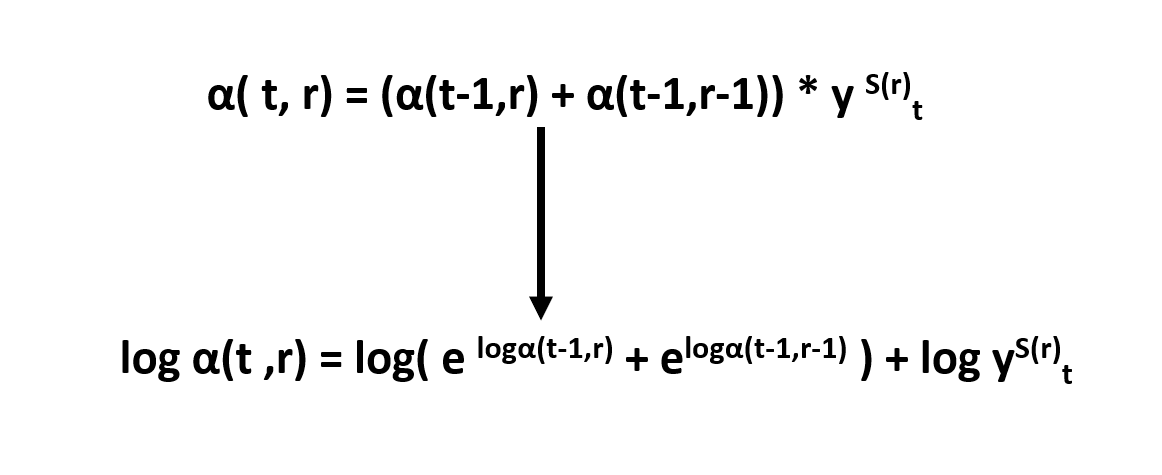
- Backward Algorith:
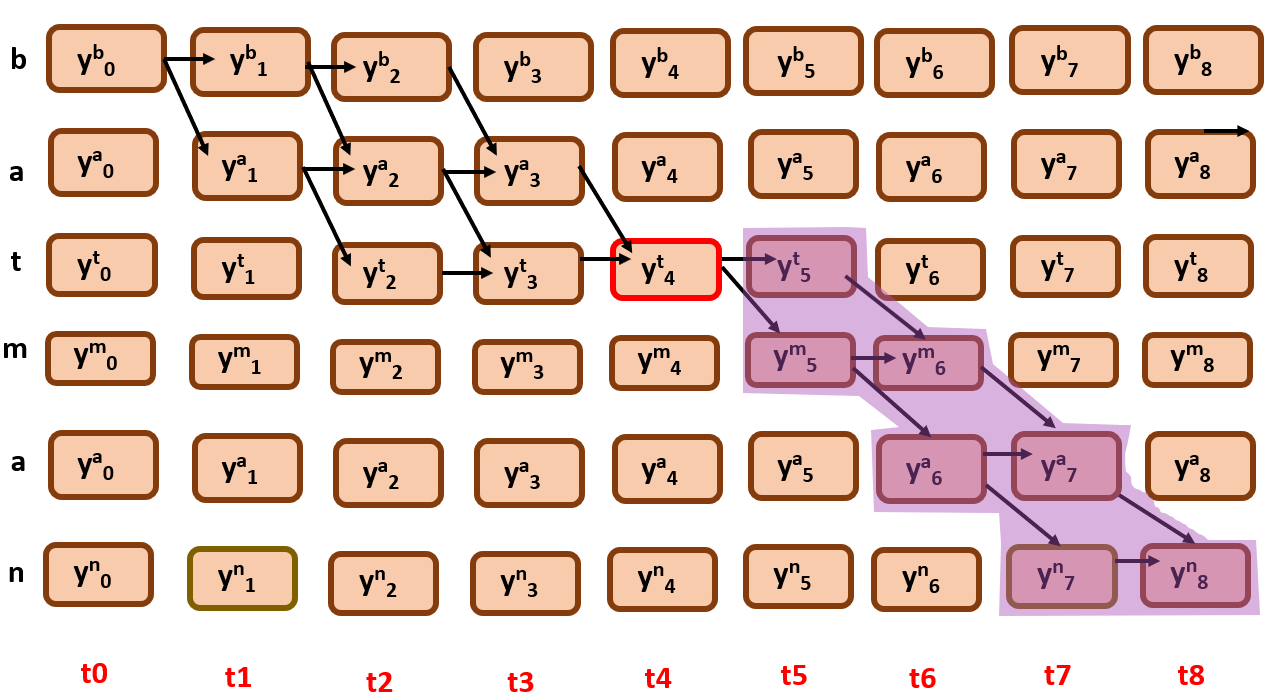
Here you can observe that we only consider edges that are coming from y4t.
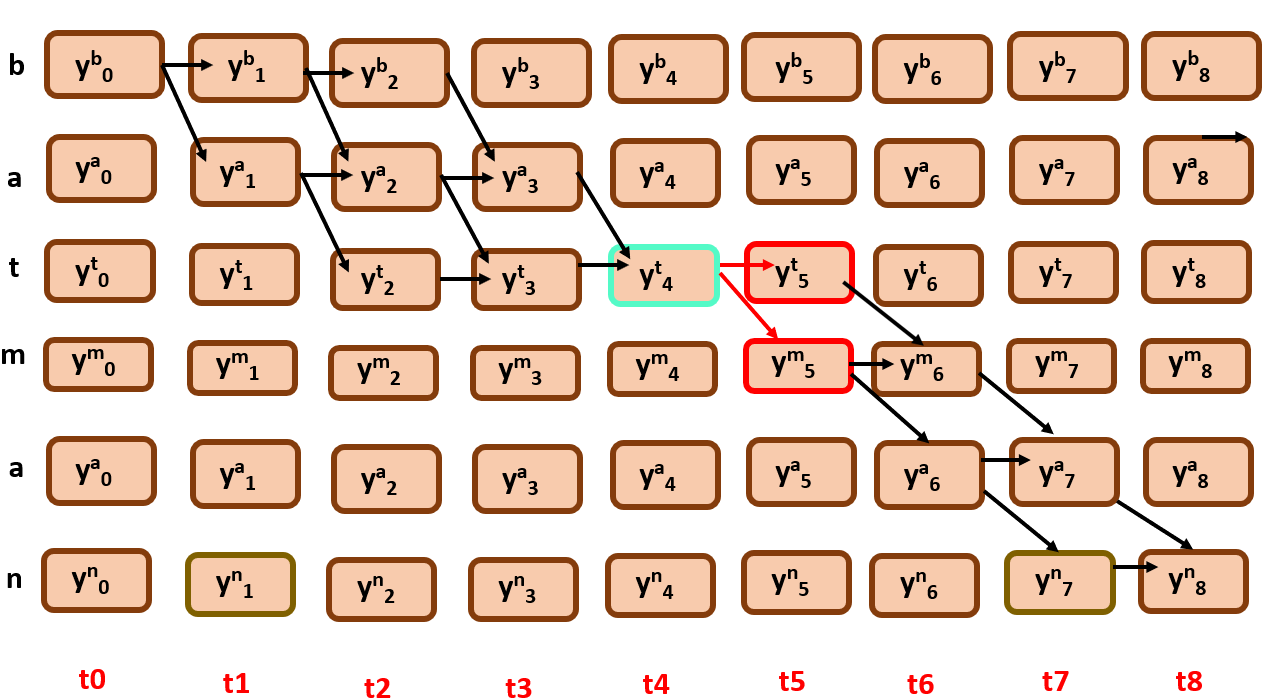
As you can see, the outgoing edges from y4t here are y5t and y5m.
- β –> denotes backward probability
We have to find out β(t=4, r=2),there can be two possibilities here as well…
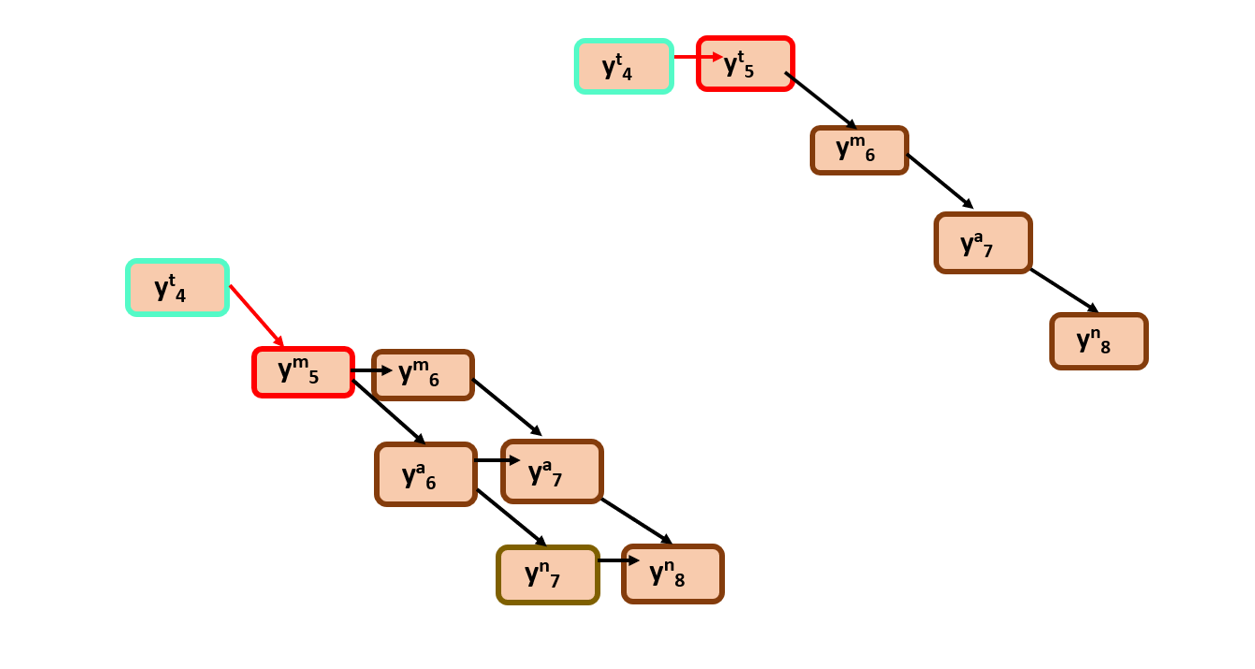
β(t=4, r=2) = Prob(sub graph beginning at (t=5,r=2))*y5t + Prob(sub graph beginning at (t=5,r=3)) *y5m
this too can also be represented as
β(t=4,r=2) = β(t=5,r=2)* yS(r)t+1 + β(t=5,r=3)* yS(r+1)t+1
the generalized form can be written as,
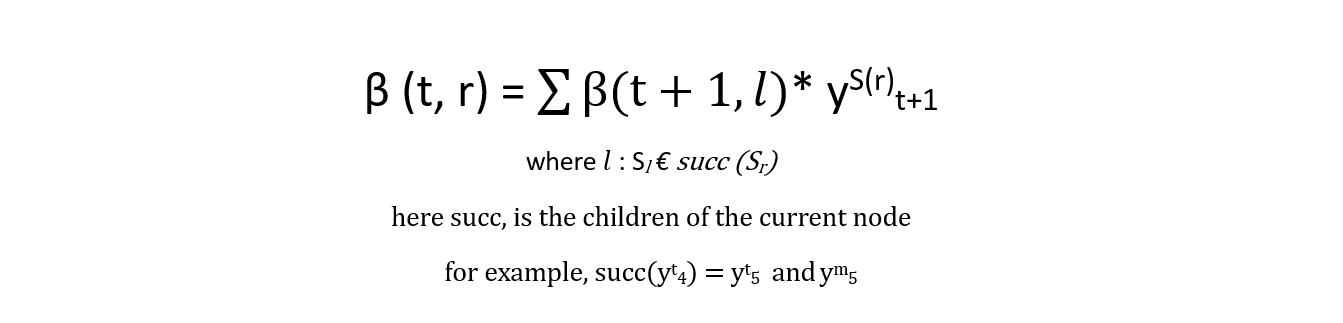
similar to forward algorithm, we use this recursion to compute the backward probability.
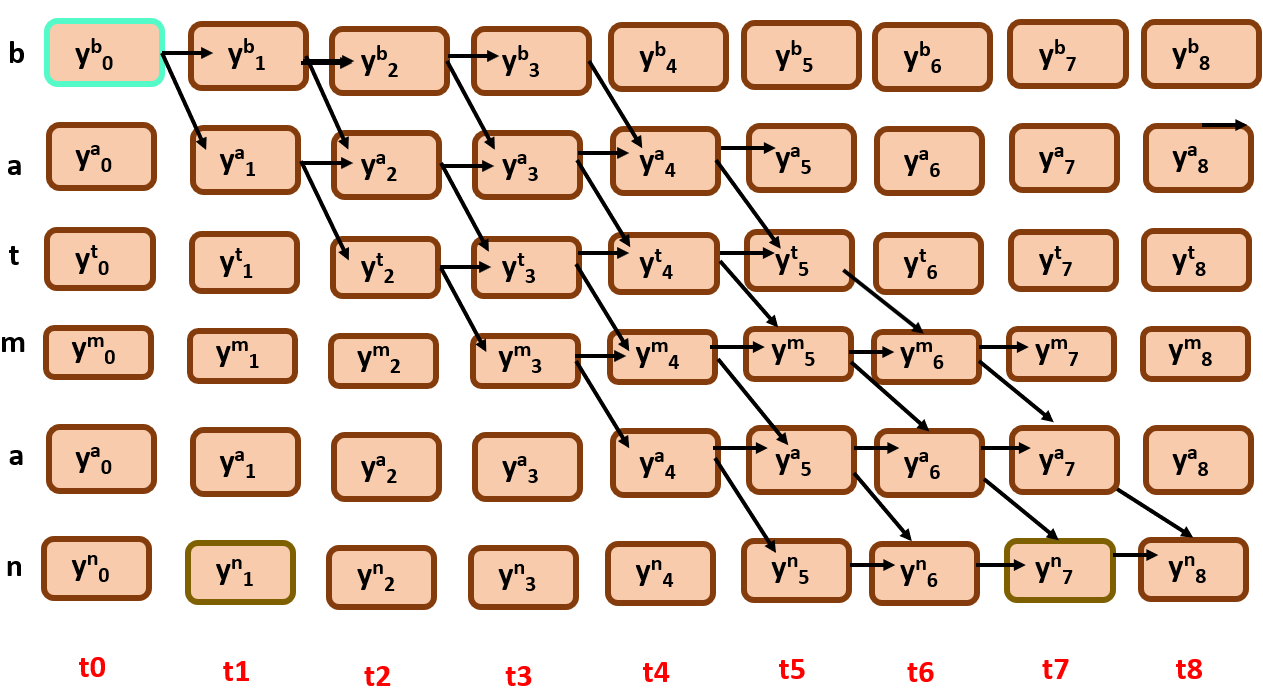
Initialization:
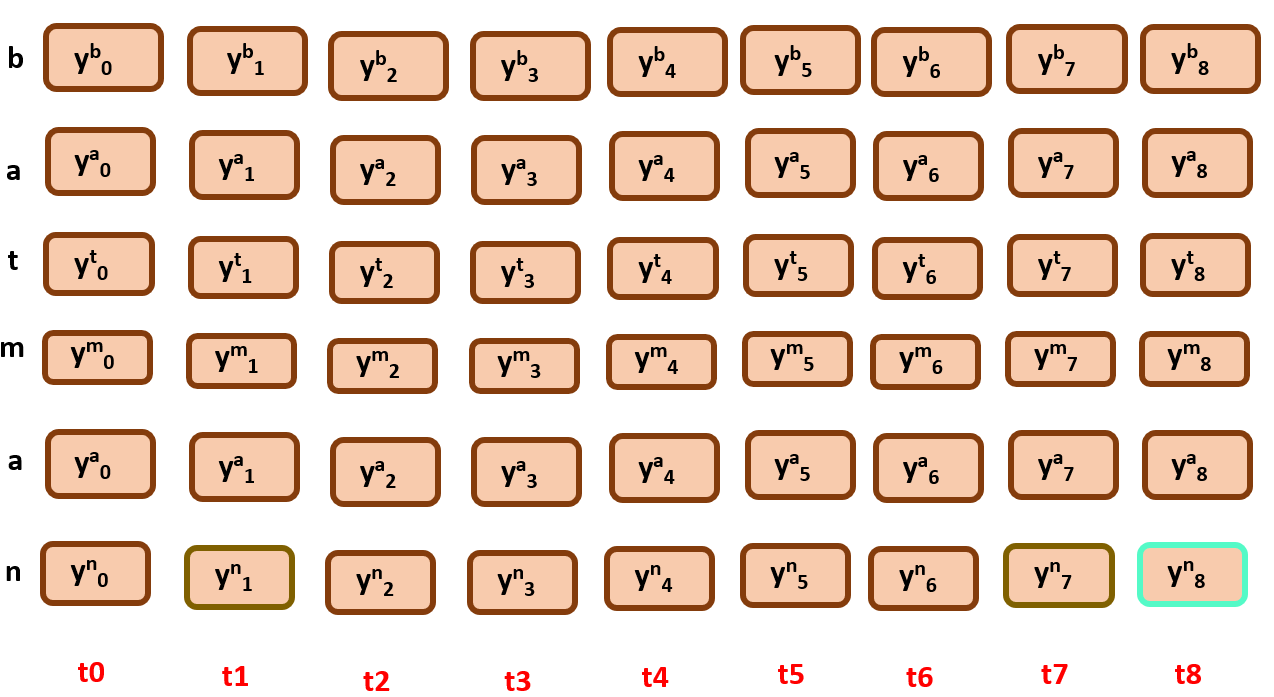
β(t=T-1, r = len(classification labels)-1) = 1 –> β(t=8, r=5) = 1 β(t=T-1, r < len(classification labels)-1) = 0 –> β(t=8, r<5) = 0
for t=T-2 to 0:
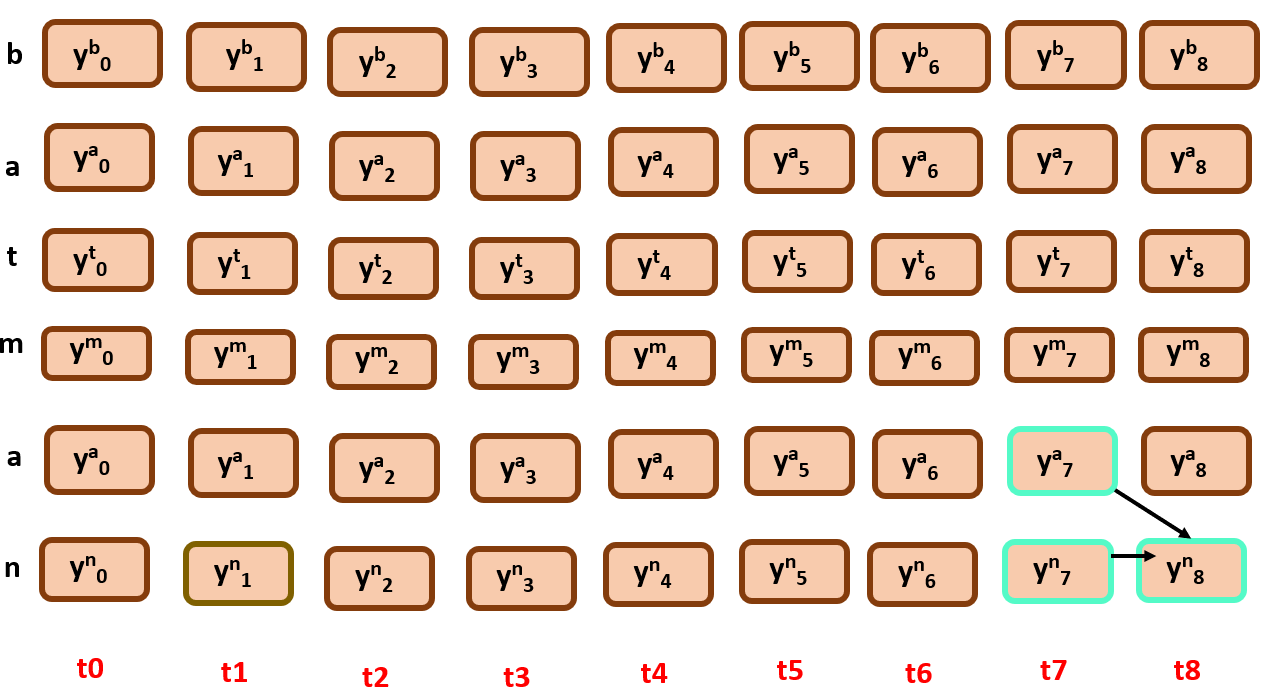
β(t=7,r=4) = β(t=8,r=4)*yS(r)t+1 + β(t=8, r =5) * yS(r+1)t+1 –> 0+ 1 * yn8
β(t=7,r=5) = β(t=8,r=5)* yS(r)t+1 –> 1 * yn8
similarly, we do It until t=0, using the recursion function defined above.
Joint Probability:
We have to find the cumulative probability combining both forward and backward probabilities.
Before that I wanted to quickly tell you that we are assuming the outputs from rnn, are not dependent with one another, so the probability nodes from time step are not related to the probability of another time step, that is the nodes are independent. We know that when two probabilities are independent, the cumulative probability will be the product of those two.
So the probability of all the paths that are going through yt4 is:
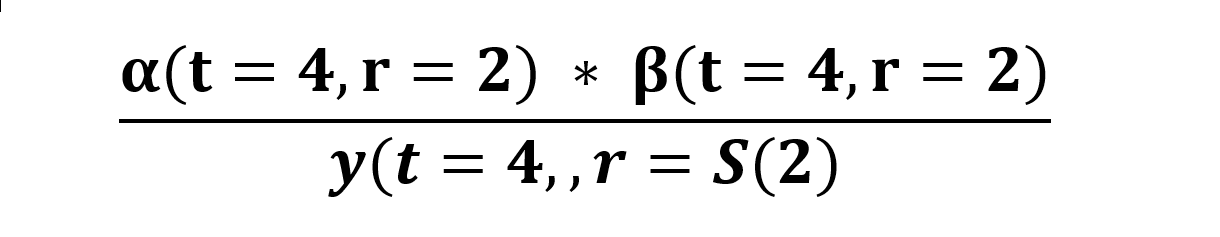
Note:
for simpler calculations in future, we included the node yt4 in backward algorithm part, so it has been repeated twice in both forward and backward probabilites, that is the reason we are dividing the probability with it too, just to avoid duplicate calculation…
Now let us calculate divergence here,
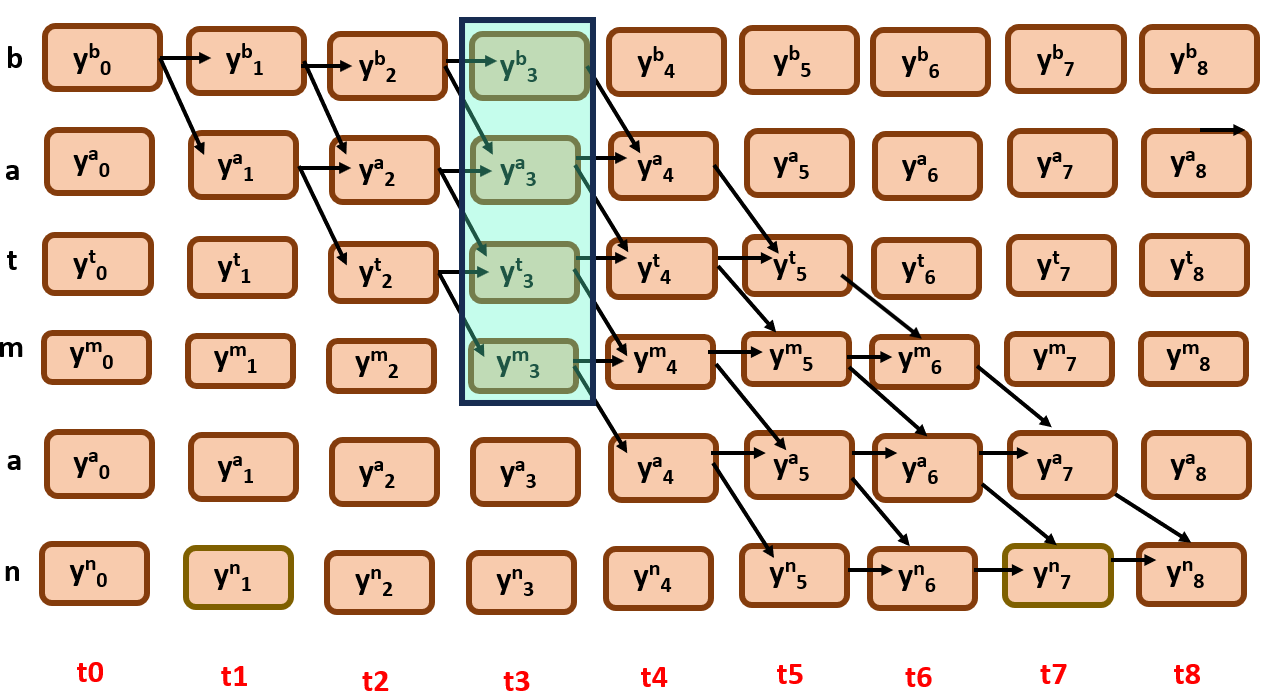
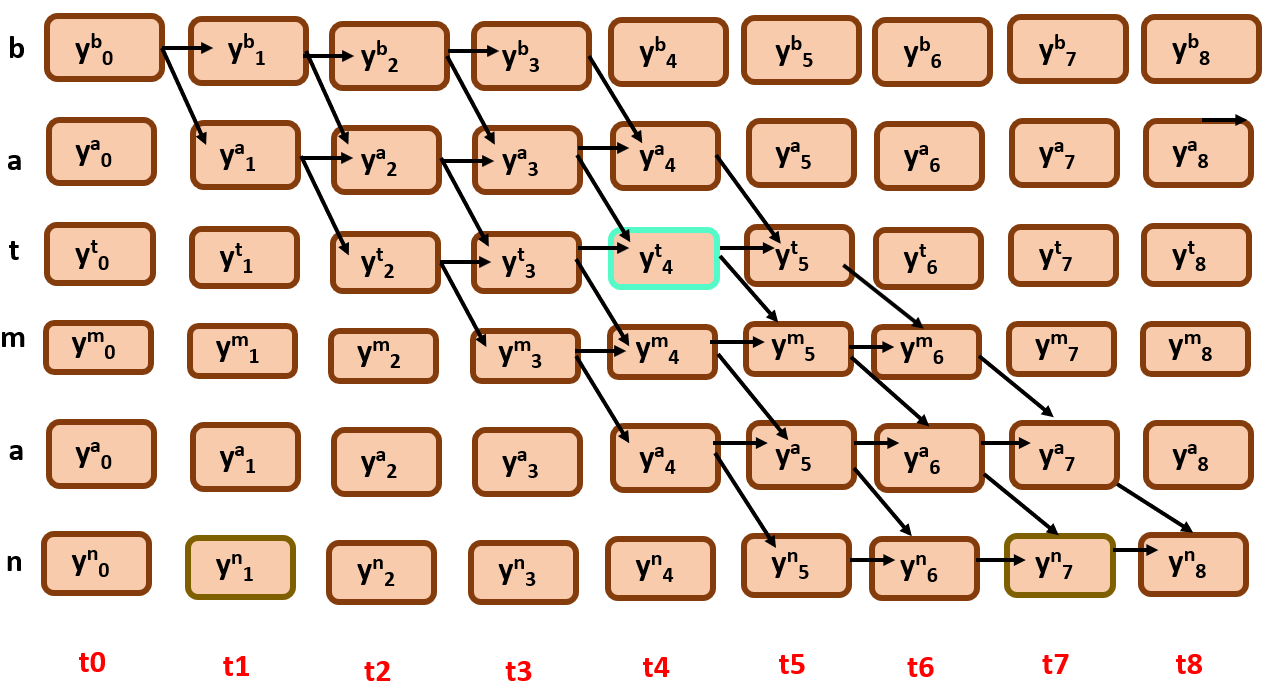
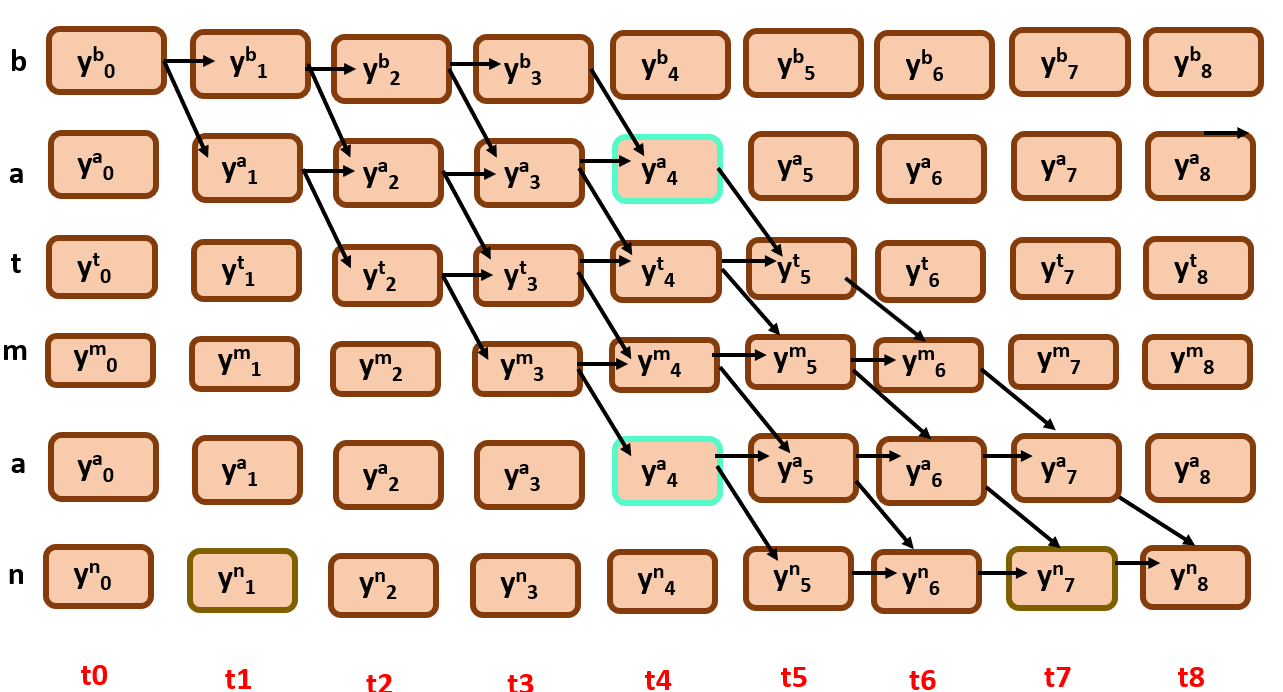
We will try to calculate the divergence at time step 3,The probability of ‘batman’ at t=3, is the sum of all probabilities of all paths through all symbols. Simply, all the nodes that are involved in formation of ‘batman’ at time = 3.
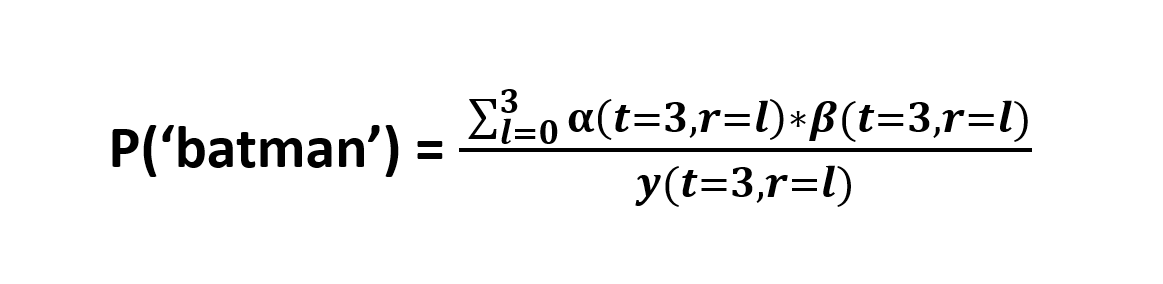
Here you can find the cruciality of forward and backward algorithms that we have discussed above, it used to calculate the Probability of all the paths that are involved in a specific node in a given time steps with dynamic approach.
We want to minimize the cross entropy between the actual and predicted probabilities, i.e. -log(prob) should be Minimized…
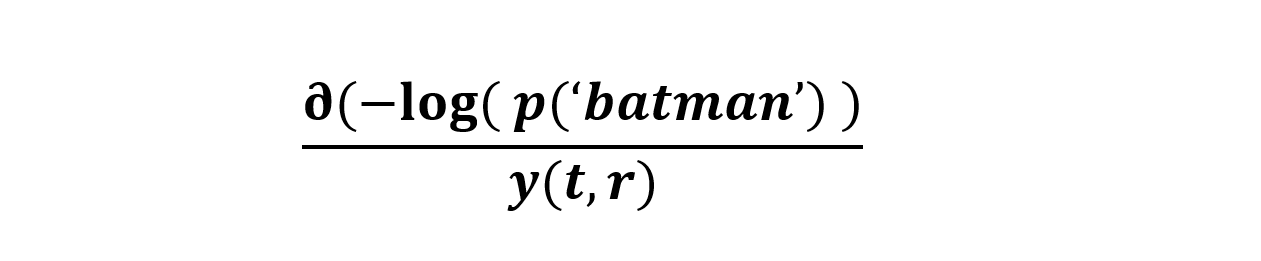
What does this mean?
We are trying to find out the amount of change for every node at different time steps
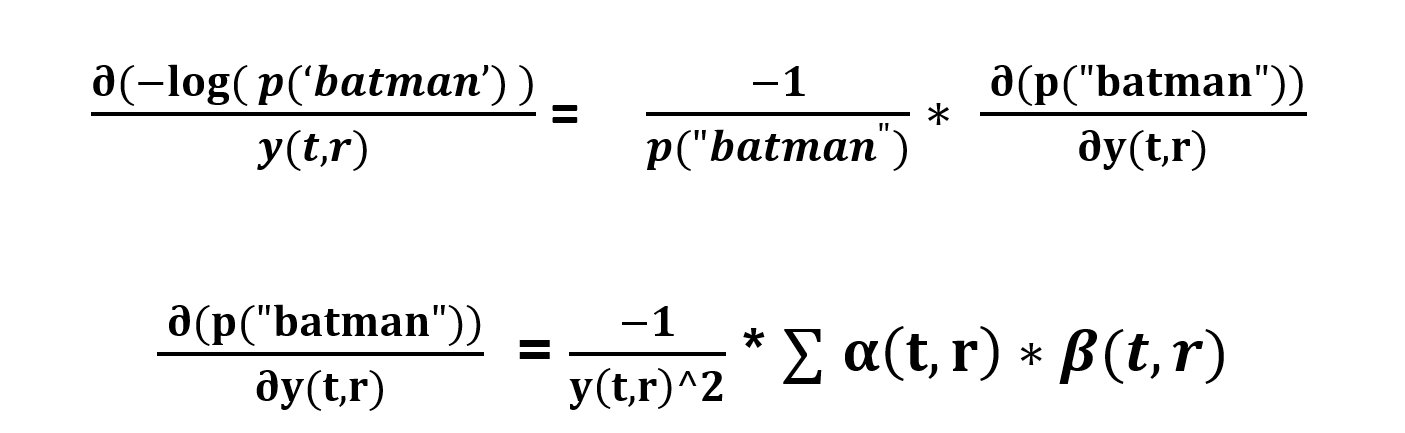
let me show you two different scenarios to calculate the divergence…
say for t=4, S(r) = ‘t’
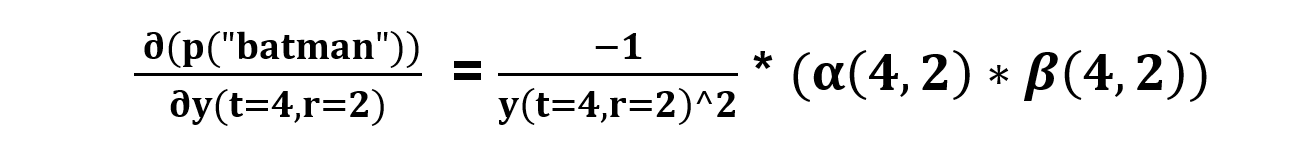
now if a character has duplicates in a single time step we simply add the possible paths from two nodes.
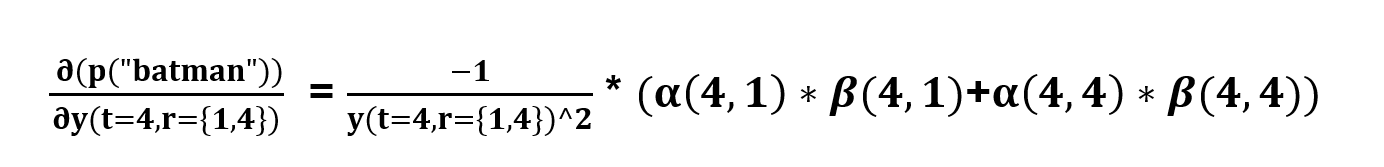
the probability of the node ‘y’ will be same for all the duplicates in a single time step
And that is it, our job is done! Now you can proudly say that you know the CTC Algorithm which is a backbone for literally any sequence problem.
Thanks for coming this far, i hope you’ve enjoyed reading it…
Do share your feedback and suggestions (if any) to my mail neerajpola2002@gmail.com.
Happy learning!