
Retrieval-Augmented Generation
You must have heard about this term booming all across the feilds of AI.
Well does the hype for it lives upto the expectations of its impact? Yess!! ofcourse, it does, and we will deep dive into its core functionality by familirizing with each of its componenets piece by piece.
Before that we will look into how an LLM generates an output without RAG to understand the need for it.
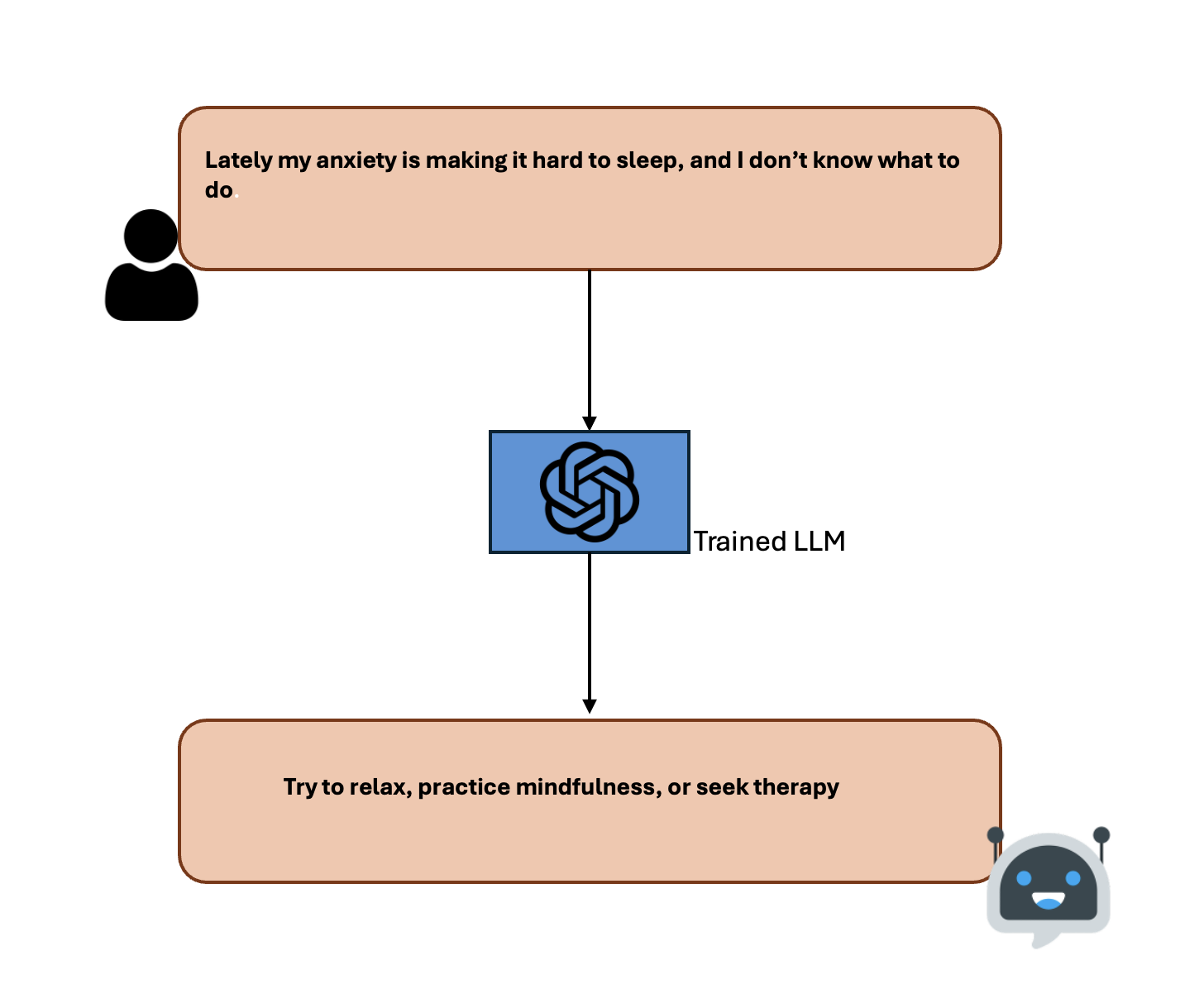
You can see the problem here, without RAG, the LLM is generating a very surface-level response without any proper guided instructions.
We can categorize this RAG into 3 types:
i. Naive RAG
ii. Advanced RAG
iii. Modular RAG
Let us get into the Naive RAG, it follows a traditional process that includes indexing, retrieval and generation
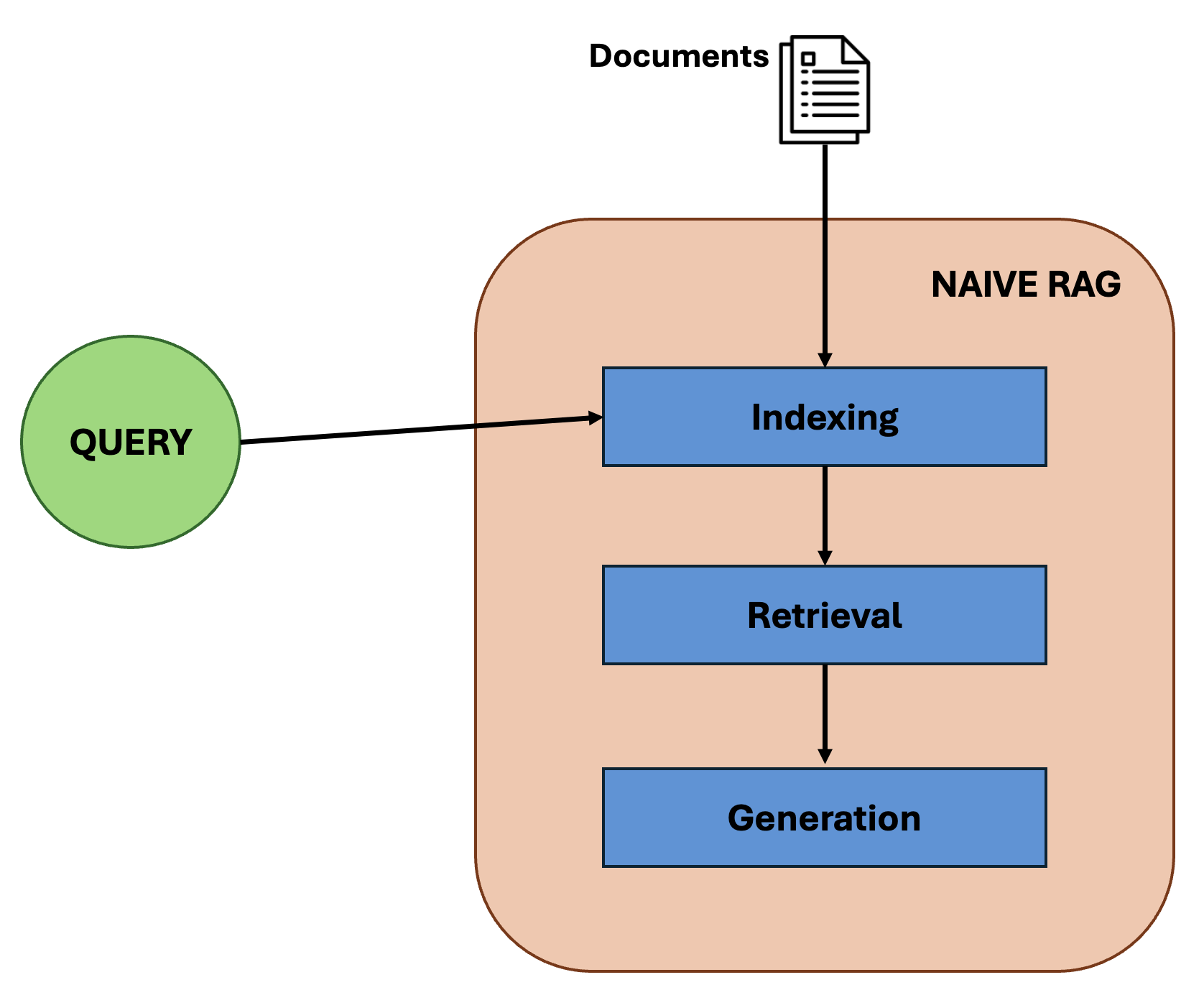
we will dive deep into each of these components.
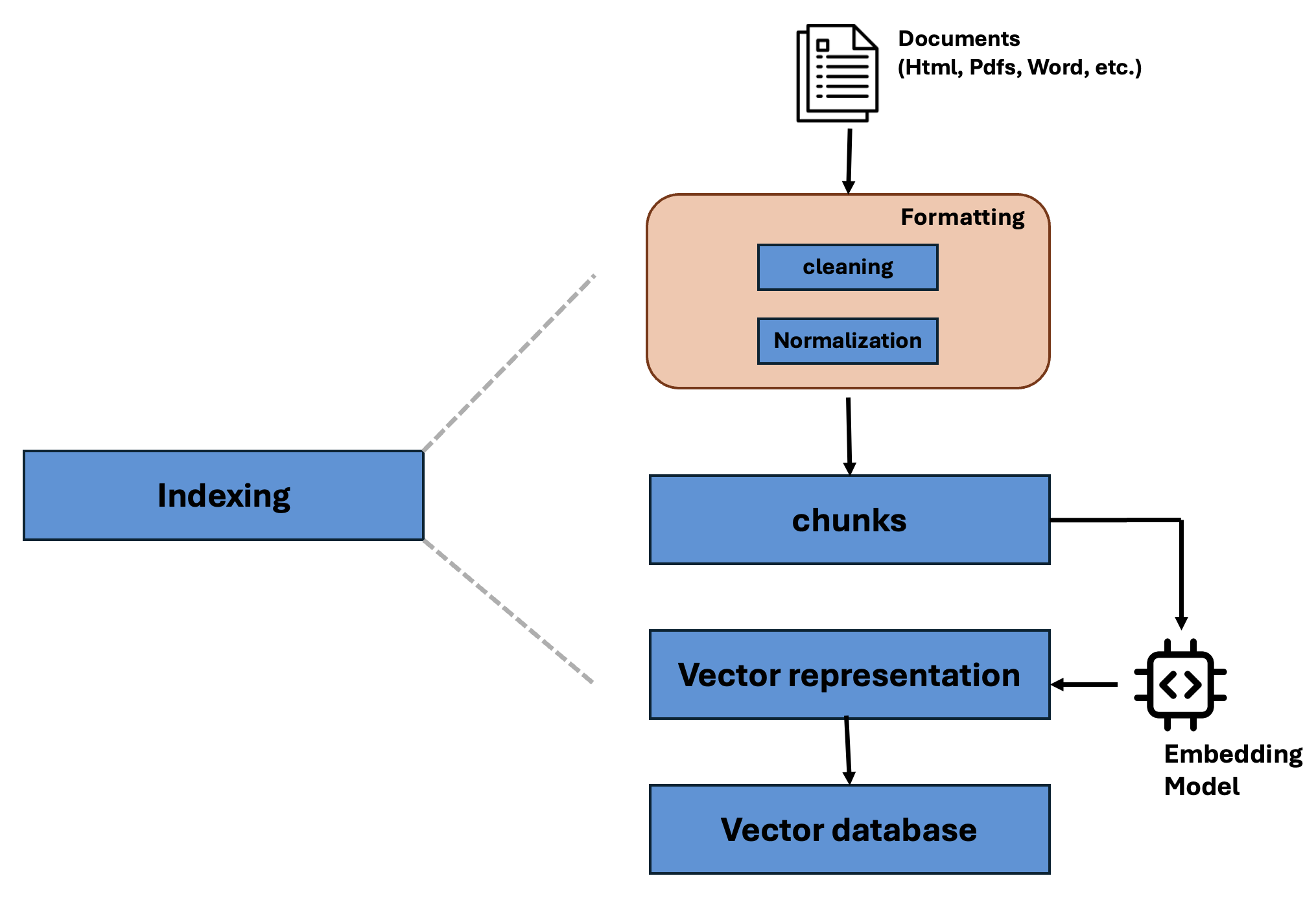
The source(documents) can be of any text type (optimizingly using these sources will be discussed later), is then passed to a stage formatting, here texts from different sources are combined, then cleaned and are normalized so that all the text is converted to uniform plain text format, this step is crucial because it does help to remove any disrepancy in wordings (CAT, Cats, cat are considered same), this formatted text is then passed to chunking where the text is split into fixed sizes, this chunks are chunks then passed into an embedidng model (sounds fancy but it is just a model which converts text to numbers so that the machines can interpret it more easily), now we have vector representations of those chunks, these vectors are stored in a vector database (optimizing this database for faster processing is discussed later).
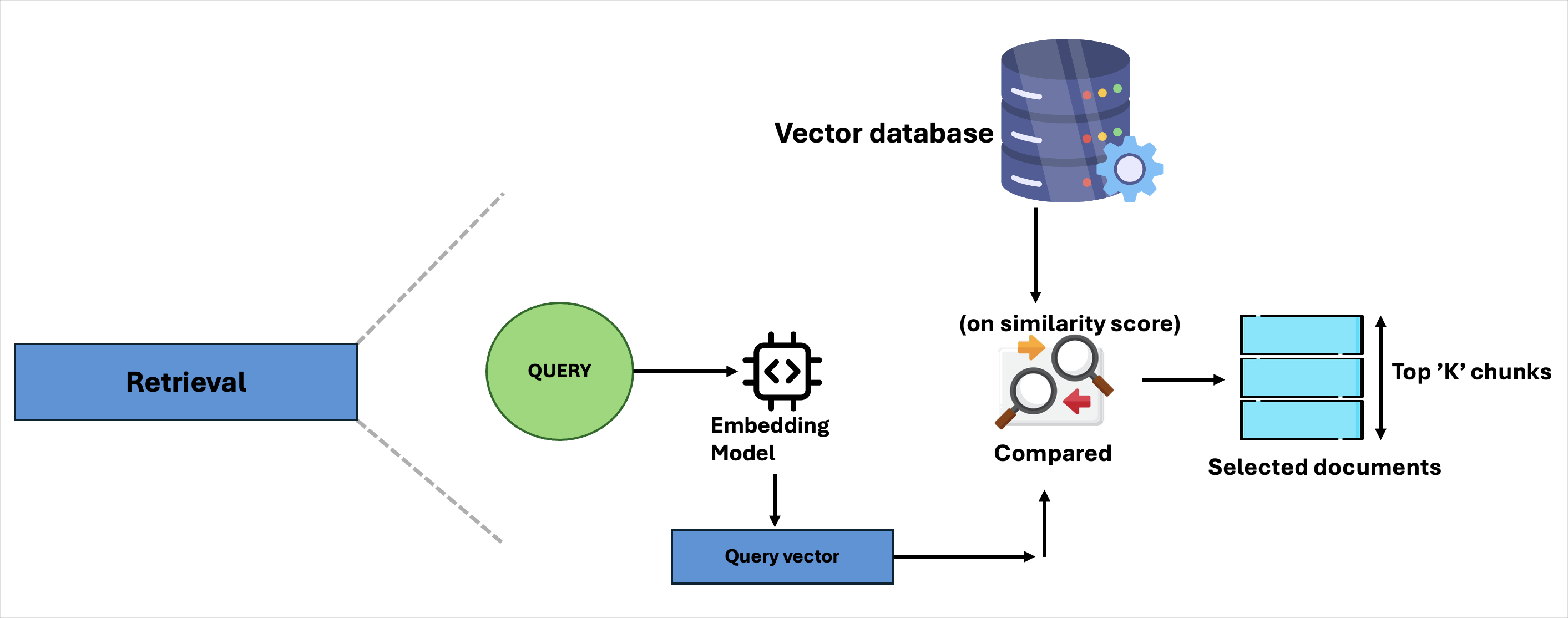
Now we will go into the retrieval phase, where the user’s query is recieved which passes into the same embedding model that was used before (for coherent flow) which generates a query vector that is compared with the vector database (previously used to store the chunks) using some similarity scores, based on the scores, some documents are selected these can be also called as top-k chunks.
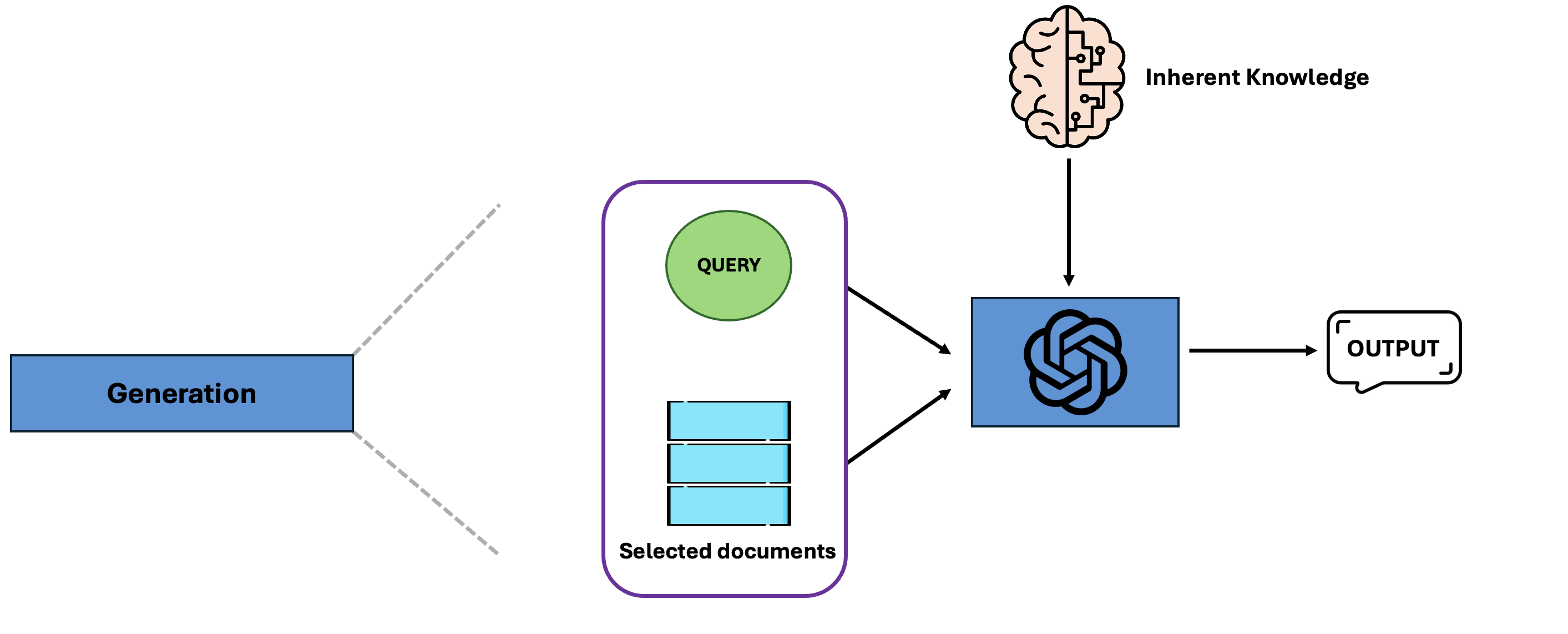
Then the initiall query along with our selected documents is given to our LLM, which either uses them as the base to generate an output or uses its inherent knowledge (the parameters that it was initially trained on) to generate an output (it generally depends on the tasks). And that is the basis of the Naive RAG. So far so good, but now we will see the need for other architectures, some drawbacks of the Naive RAG:
-
Retrieval Challenges : When similarity scoring is off, the system retrieves things that look kind of right but miss the intent, say when the query is about a fruit ‘apple’ but it finds chunks like ‘apple products’ to be more silmilar than the fruit itself.
-
Gnerational Difficulties : When the model starts to halucinate and just blindly relies on its previous knowledge without using the help of top-k chunks, this may cause the model to give outputs that are outdatated.
-
When k is just 1: when only one chunck is retirieved by the similarity scores, it may not be adequate for the model to acquire context information.
-
Over rely on top-k chunks: sometimes the model may just give the chunks as an output, facing a critical ‘overfitting’ issue.
To overcome this, Advanced RAG is introduced, it mostly focuses on improving retrieval phase and optimizing the indexing.
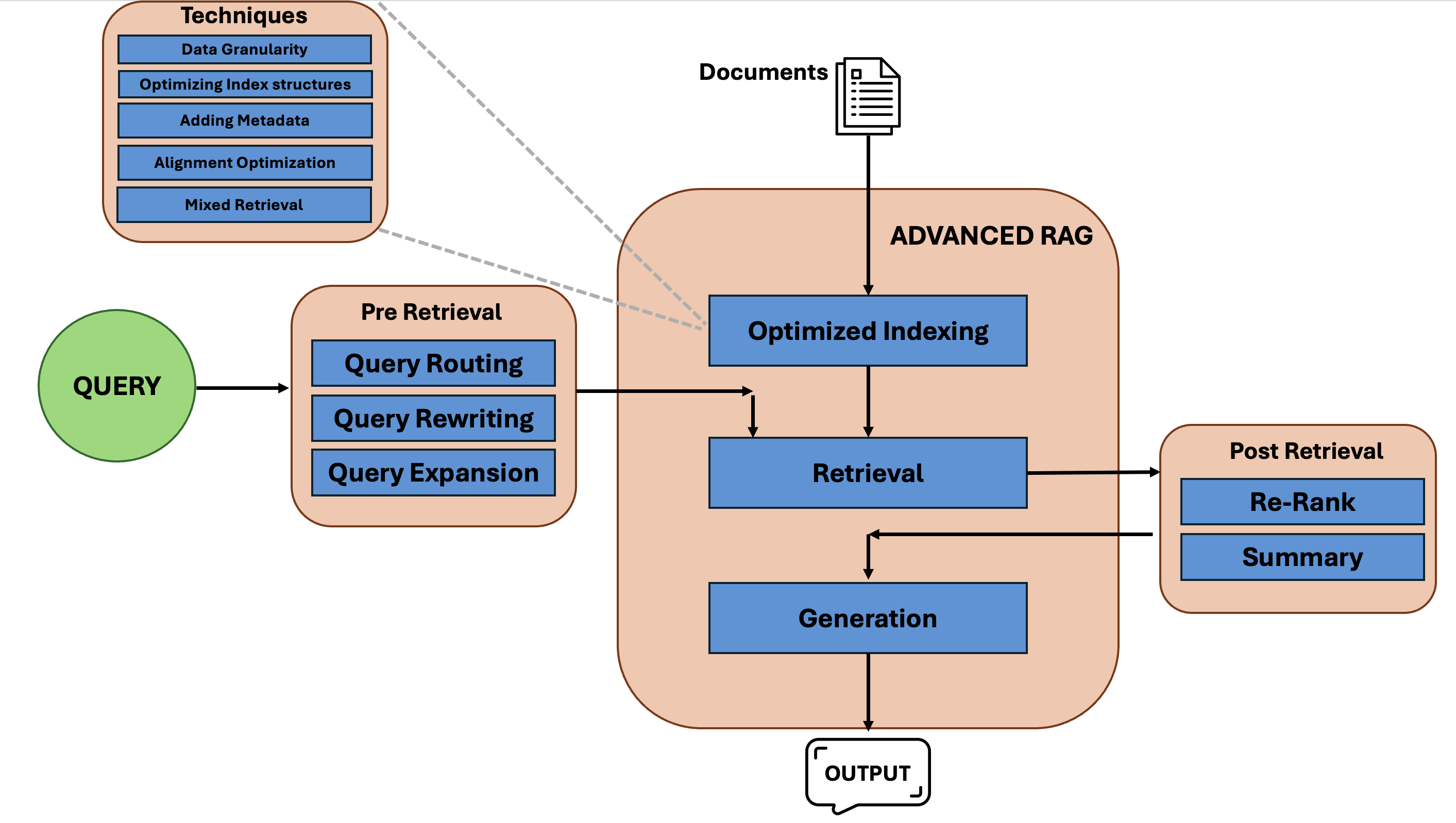
first we will go into how is indexing is optimized with different techniques
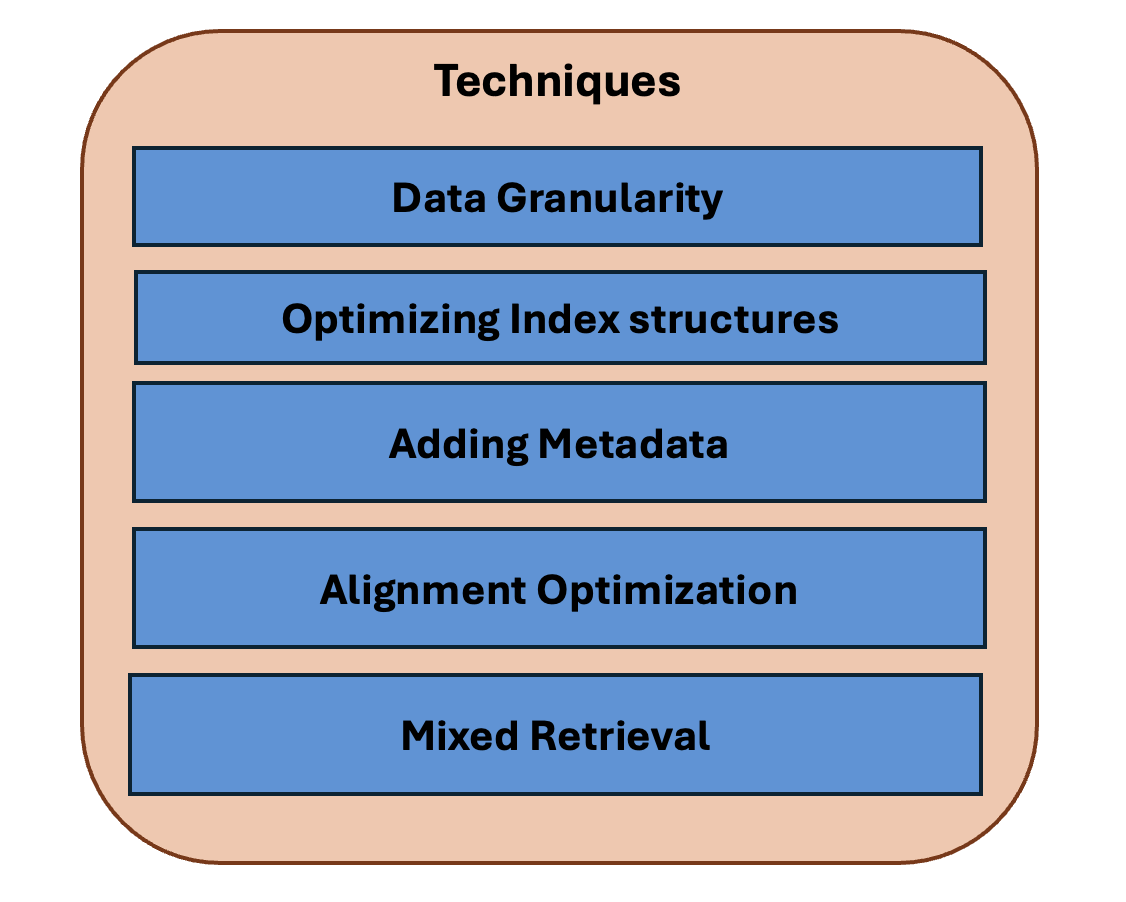
1. Data granuarity : instead of creating chunks of constant sizes (which is done in Naive RAG) we used chunking with differnt sizes to create meaningfull structural chunks. In constant numbered chunking, sometimes headings, passages, keypoints from documents are either chunked paritally or totally goruping all of them, where as in data granularity differnt structures (headings, passages, keypoints..) are chunked uniquely.
2. Optimizing Index Structures:
In Naive RAG, query indexes are directly compared for similarity check with all the dense vectors in the vector database resulting in retrieving partially knowleged chunks (that can only understand the semantic nature but not the syntactic nature) with slower retrieval rate. So we use different optimized techniques like hybrid indexing and Hierarchial indexing.
A. Hybrid indexing: It uses combination of both sparse (syntactic/keyword based) and dense (semantic/meaning based) vecotrs. B. Hierarchial Indexing: It uses advanced approaches like memory trees, where the first retrieval process is drilled to documents or high-level sections and then drilled down into chunks within them.
Assume you are in a library with books all over the racks with no proper indications, can you search down for a book (that you properly don’t know the name of but know what genre it is and what it contains)? Sounds impossible right? Now say you know the book name, although you have to search all the racks one by one which takes a huge amount of time, now this is what happening in the general naive RAG indexing, where the books are the vector chunks, query is your book, and racks in the library is a vector database.
Now imagine a library, where two super smart librarians helping you. One listens to your explanation and instantly understands what you mean (semantic match). The other scans for exact words or phrases you mention (syntactic match). Now these two librarians know what you are looking for, but it would be impractical for them to search it for all over the racks (which are unorganized and all the books are randomly placed), thus to prevent from that, they organize their racks in a way where every genre (or rather any classifiable thing) is placed systematically, so that they can narrow iit down in an optimal way.
This is how, combination of Data granularity and Optimzing idexing helps in RAGs as well.
3. Adding Metadata: Adding metadata in RAG is like attaching tags or labels to vector chunks (something like a dictionary with keywords along with their values), which can be used to filter the results (like finding all the books by a certain author),and it also supports the hybrid indexing.
4. Alignment Optimization: It is to ensure that every chunk in the index is actually useful and relevant to likely queries, not just match because it mentions certain terms.
Assume walking back into library asking how transformers work. In a naive RAG setup, the librarian hands you three pages: one says “Transformers are popular,” another lists “BERT, GPT,” and a third starts mid-sentence with “…due to self-attention.” They all mention transformers but none actually explain them. In a better library with alignment optimization, the pages were pre-checked. The librarian gives you a clear, meaningful information, something you can actually learn from.
5. Mixed Retrieval: Similar to Hybrid indexing which helps to organize the vector chunks, Mixed Retrival uses both of the semantic and syntactic informations to give a more impactful output.
Assume you have two friends one has a sharp memory for names, dates, and exact terms (syntactic), while the other is great at understanding the big picture, “what” and “why” of things (semantic). You ask them about transformers. The first friend gives you precise terms like “self-attention” and “positional encoding” but struggles to explain how it all fits together. The second friend walks you through how transformers work, but doesn’t use the exact terminology. Only when you combine both the detailed terms and the conceptual explanation, you get a full, meaningful answer. That’s exactly what Mixed Retrieval does, it blends keyword-based (sparse) and meaning-based (dense) retrieval to give you the most complete and useful context possible.
Great, now let us move with pre-retrieval techniques in the Advanced RAG:
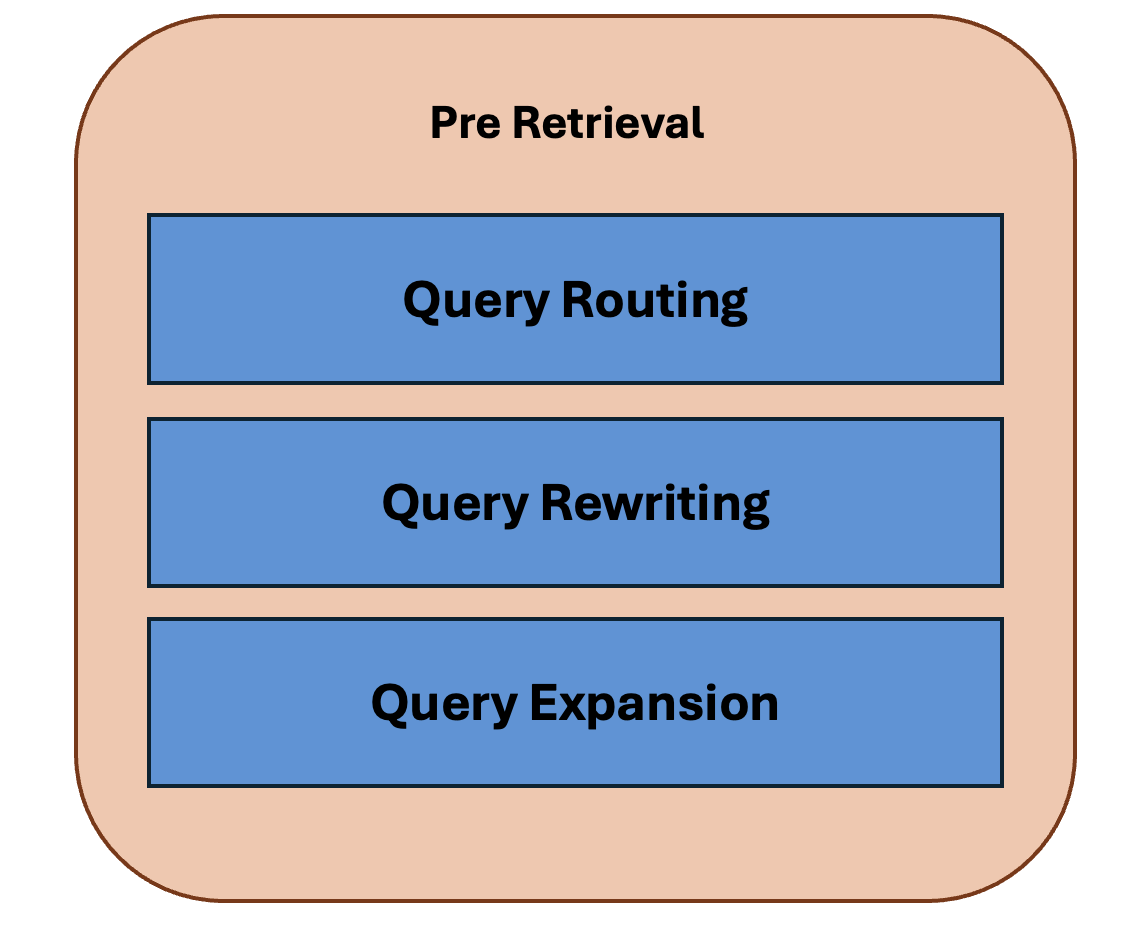
Query Routing: It is the process of deciding where a query should go based on its type, topic, or intent, before performing retrieval. This helps the RAG not to treat all the queries similarly, well how does that help? The vectors can be from different data sources (it can be from either SQL database,json, or even with an API call), because of this large data it is inefficient to send all the queries to all the data sources, having a routing mechanism helps to navigate their correct destination quickly.
Assume, you are back to that same library again, without a help desk, you want to read a book of specific author in fiction, although you have got sorted with finding where the section is (thanks to our index optimization techniques), there would still be a lot of racks for that section which is cumbersome to search for, now say you have an help desk, he would easily navigate you to that particular rack instantly.
Query Rewriting & Query Expansion:
Once the relevant context is gathered with the help of processing our queries, we will have a numerous vectors retrieved from the vector database, the number can sometimes be so huge, that when we give all of this retrieved vectors to the frozen modell (our LLM) it may get overloaded with that much of information, resulting in an abysmal performance, so what do we do now? we can process the retrieved vectors called Post Retrieval process.
Post-Retrieval RAG: Here, instead of giving all retrieved information at once, we try to rank and summarize the vectors by the following ways.
-
Re-ranking Chunks: Even after similarity scoring, not all retrieved chunks are equally useful. Re-ranking helps reorder them so that the most relevant pieces of information rise to the top and are positioned strategically in the prompt. Frameworks such as LangChain, LlamaIndex, and HayStack implement these strategies effectively.
-
Context Compression: Instead of passing everything into the LLM, context compression selects and summarizes the essential parts of the retrieved text. This ensures that critical sections are emphasized while trimming away redundant or irrelevant content. The result? A more focused and concise prompt that the LLM can handle efficiently.
Think of it as preparing notes for an exam: you don’t want to cramp the entire textbook into your memory. Instead, you highlight key formulas, diagrams, and explanations that maximize understanding while minimizing overload.
By combining retrieval with smart post-retrieval optimization, RAG pipelines ensure that the LLM not only has access to external knowledge but also uses it efficiently and meaningfully. This marks the shift from a naïve setup to a truly advanced and practical RAG system, one that balances depth, efficiency, and precision.
Now as we have explained the theoretical part of RAG, let us get into the practical part where we can see the implementation of what we have seen throughout. Let us gets our hands dirty.
Thanks to Langchain community, we do not have build the indexing, retrieval and generation part on our own, we can use the base models from them.
Working with RAG used to feel like building a house brick by brick, writing code for loading documents, splitting them into chunks, generating embeddings, setting up retrieval, and then finally plugging it all into a model. With LangChain and LangGraph, it’s like someone handed us a toolbox with everything neatly organized. LangChain takes care of the heavy lifting like reading documents, breaking them down, turning them into embeddings. While LangGraph lets us connect these pieces together like a flowchart. Instead of worrying about wiring every detail ourselves, we get to focus on the fun part: shaping the workflow and fine-tuning how the system talks back to us.
LangChain is like the foundation toolkit for building with LLMs. It gives us ready-made components to handle the tricky parts of RAG, things like document loaders (to pull in knowledge from PDFs, text files, or websites), text splitters (to break big documents into manageable chunks), and embedding wrappers (to convert those chunks into vectors). Instead of reinventing these utilities ourselves, LangChain packages them in a consistent way, so we can focus on what matters: deciding how information flows and how the model should use it. This makes the indexing and retrieval process smooth and reliable.
LangGraph, on the other hand, is like the project planner that helps us stitch all those LangChain pieces into a clear pipeline. Think of it as drawing a flowchart where each step of indexing, retrieval, re-ranking, generation is a node that connects to the next. It helps developers build structured, reusable workflows that are easy to reason about, test, and extend. With LangGraph, we don’t just have scattered tools, we have an organized system where the entire RAG process can be visualized and controlled. This makes experimentation and scaling much simpler.
In this project, we’re tackling one of the most delicate areas, mental health support. Users interact with open-ended questions about how they feel. But answering such queries responsibly requires more than surface-level knowledge; it needs context from trusted sources like medical textbooks and research materials. This is where RAG steps in, by pulling in relevant, evidence-based information and blending it with the LLM’s reasoning ability, we can deliver responses that are not only empathetic but also grounded in real knowledge.
Below are the following imports that were necessary for the project:

dotenv -> was used to import the keys for the apis used like openai(our initial base model that we wanted to create our RAG pipeline with)
langchain.text_splitter -> used for chunking
langchain_community.document_loaders -> to load the documents from the data (which were in the form of pdfs or text files)
OpenAIEmbeddings -> our open ai model for indexing and creating the embeddings(vecotrs)
So, what was our first step to build a RAG? To collect relevant data, for this I had browsed different textbooks that deal with the people who are suffering from anxiety or depression, and some steps to resolve them. Now keep in mind that the interent is a sea and there are lot of resources targeting this, but to choose the books that are authentic, shown the positive results from following the steps described is key here. If we just surf throughout the internet and just collect everyhing that has the term anxiety or depression will again lead our model to give results that are not accurate. So I had mostly collected the data or textbooks published in any journals or something that had shown some positive results.
You can browse them in my github repo
So after the collection of data, our next step will be indexing.
heads up, I will not be going into the details for creating an api for databse to store our vectors as that will be something irrelevant to our scope, although if you are interesed you can look that up in my github repo.

The above code is just a function used to load data from pdfs or text files. PyPDFLoader and TextLoader are from langchain.

This LangChain utility takes long documents (like PDFs or textbook text files) and breaks them into smaller, manageable text pieces (chunks). I had assigned chunk_size=1000 (small enough to fit comfortably into an LLM’s context window, but large enough to carry meaningful context, but this can be tweeted according to the task) and chunk_overlap=200 this ensures when one chunk ends, the next one overlaps by 200 characters. This ensures important ideas at the boundary of chunks aren’t lost.

This piece of code is responsible for taking the text chunks we created earlier and turning them into embeddings before storing them in a database. First, it initializes the OpenAIEmbeddings model, which converts text into numerical vectors that capture meaning. Then, for each chunk, it generates an embedding using embed_query and converts that embedding into a byte format so it can be stored efficiently in the database. Along with the embedding, the original chunk content and its source filename are also inserted into a table called rag_chunks. This way, each piece of text is linked to a vector representation and its origin, making it easy to retrieve semantically similar information later during the retrieval step of RAG.

This part of the code handles the retrieval step in our RAG pipeline, where we search the database ( I had used TiDB, but there are many other choices as well for the vector database) for the most relevant chunks based on a user’s query. The function get_embeddings() is wrapped with @lru_cache, meaning the embedding model is loaded only once and reused across calls to save time and resources. When a query is received, it is converted into a vector (q_emb) using the same OpenAI embedding model we used for storing chunks earlier.
Next, the function connects to the database and fetches up to row_limit stored chunks and their embeddings. For each chunk, it calculates the cosine similarity between the query embedding and the chunk embedding, this measures how semantically close the two pieces of text are. The scores are then sorted in descending order, and the top k most relevant chunks are returned.
In short, this function is the heart of retrieval: it transforms the query into a vector, compares it against stored knowledge, and brings back the most relevant context that will later be fed into the LLM for generating an answer.

This last function is really where all the moving parts finally come together. When someone asks a question, ask_rag() doesn’t just throw it blindly at the modell, it first goes digging through our stored knowledge using search_tidb(), pulling out the three most relevant pieces of information it can find. Think of it like gathering notes before giving advice: the system pauses, looks at what it already knows, and then organizes those notes into a clear context.
That context is then gently woven into a prompt designed for the model, one that frames the assistant as supportive, empathetic, and practical, while also reminding it to handle sensitive moments like crisis situations with care. Once the groundwork is laid, the question and the context are handed over to the OpenAI model, which produces a response that feels not only informed but also human and compassionate.
In short, ask_rag() is the heart of the pipeline. It’s where retrieval meets generation, where stored knowledge and AI reasoning blend together to create answers that are meaningful, grounded, and kind.
And you can see the final output below.
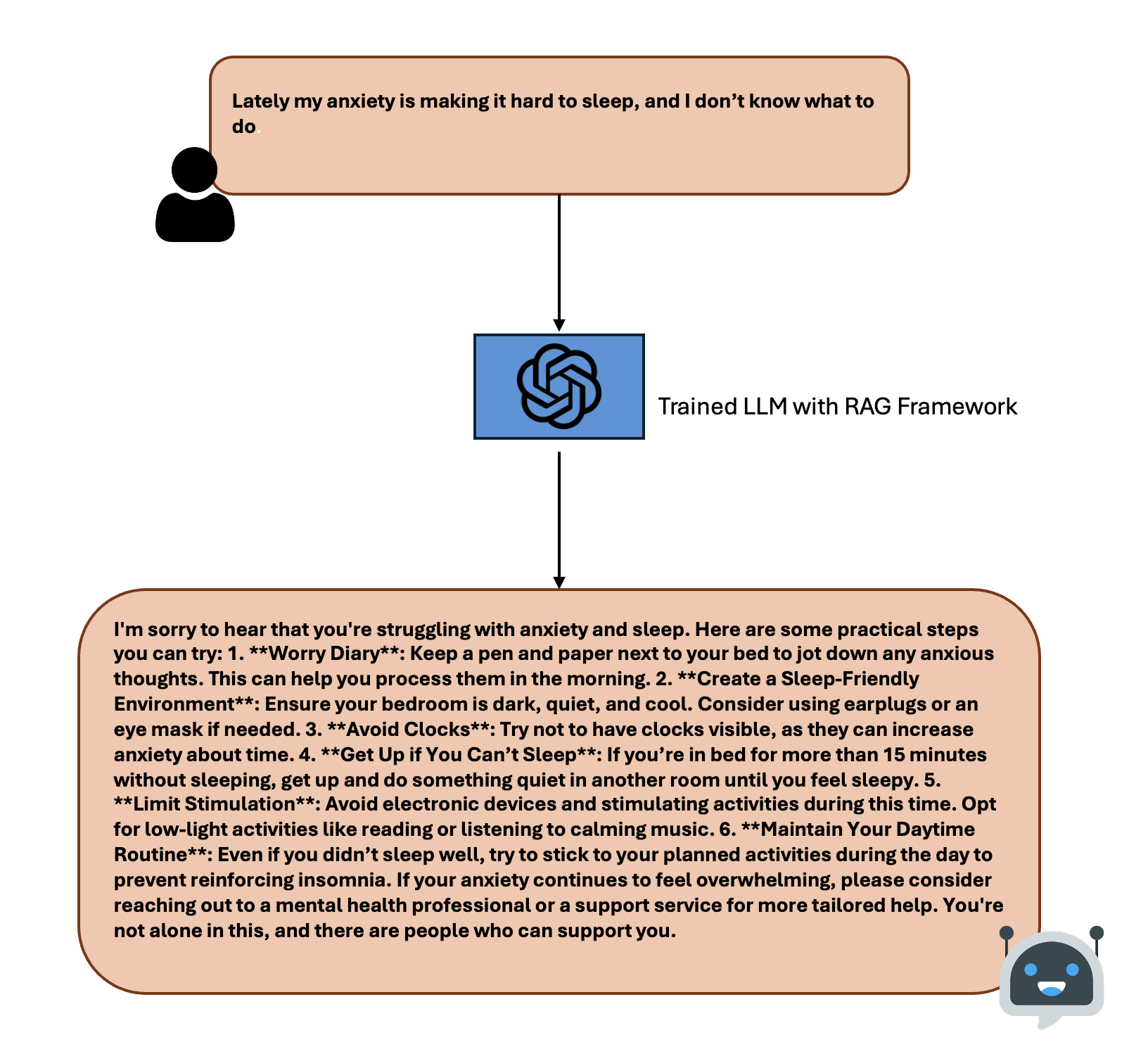
The langchain made our job easy, but learning the stuff behind the RAG framework made us to create more accurate respones and selection of the data is critical.
Thanks for coming this far, i hope you’ve enjoyed reading it…
Do share your feedback and suggestions (if any) to my mail neerajpola2002@gmail.com.
Happy learning!